
Machine Learning towards Intelligent Systems
The emergence and continued reliance on the Internet and related technologies has resulted in the generation of large amounts of data that can be made available for analyses. However, humans do not possess the cognitive capabilities to understand such large amounts of data. Machine learning (ML) provides a mechanism for humans to process large amounts of data, gain insights about the behavior of the data, and make more informed decision based on the resulting analysis. ML has applications in various fields. This review focuses on some of the fields and applications such as education, healthcare, network security, banking and finance, and social media. Within these fields, there are multiple unique challenges that exist. However, ML can provide solutions to these challenges, as well as create further research opportunities. Accordingly, this work surveys some of the challenges facing the aforementioned fields and presents some of the previous literature works that tackled them. Moreover, it suggests several research opportunities that benefit from the use of ML to address these challenges.[2]
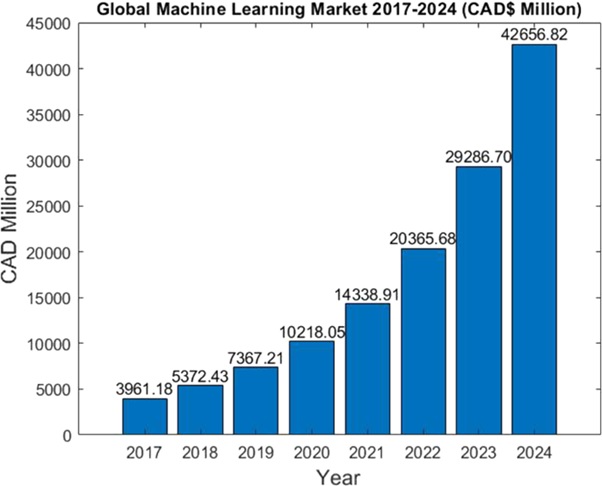
Figure 1. Machine learning towards intelligent systems
Figure 1 shows the research activities of our group are focused on machine learning, a scientific discipline in the intersection of computer science, statistics, and applied mathematics. Over the last decades, the importance of machine learning has continuously grown, and meanwhile, the field has developed into one of the main pillars of modern artificial intelligence as well as the emerging research field of data science. [1]
Uncertainty and Preference in Machine Learning
Much of our research centers around two key cognitive concepts of artificial intelligence: uncertainty and preference.
Machine learning is essentially concerned with extracting models from data and using these models to make predictions. As such, it is inseparably connected with uncertainty. Indeed, learning in the sense of generalizing beyond the data seen so far is necessarily based on a process of induction, i.e., replacing specific observations by general models of the data-generating process. Such models are always hypothetical, and the same holds true for the predictions produced by a model. In addition to the uncertainty inherent in inductive inference, other sources of uncertainty exist, including incorrect model assumptions and noisy data. Our research addresses questions regarding appropriate representations of uncertainty in machine learning, how to learn from uncertain and imprecise data, and how to produce reliable predictions in safety-critical applications.
The notion of "preference" has a long tradition in economics and operational research, where it has been formalised in various ways and studied extensively from different points of view. Nowadays, it is a topic of key importance in artificial intelligence, where is serves as a basic formalism for knowledge representation and problem solving. The emerging field of preference learning is concerned with methods for learning preference models from explicit or implicit preference information, which are typically used for predicting the preferences of an individual or a group of individuals in new decision contexts. While research on preference learning has been specifically triggered by applications such as "learning to rank" for information retrieval (e.g., Internet search engines) and recommender systems, the methods developed in this field are useful in many other domains as well.[1]
References:
- https://en.cs.uni-paderborn.de/is
- https://arxiv.org/abs/2101.03655
Cite this article:
Thanusri swetha J (2021), Machine learning towards intelligent systems, Anatechmaz, pp. 29
Recent Post
-

A Review of Chatbot Technology
A chatbot is an artificial intelligence (AI) software that can simulate a conversation (or a chat) with a user in natural language...
-
The Future Technologies of Extended reality (XR) in HealthCare
Extended reality (XR) is one of the key technologies shaping up the future of healthcare...
-

An Overview of Facial Recognition System
A facial recognition system is a technology capable of matching a human face from a digital image...
-

The Evolution of Internet of Medical Things (IoMT) in Healthcare
The IoMT market consists of smart devices, such as wearables...
-

The Features of Moorebot Scout: AI-Powered Autonomous
Scout is the world-first autonomous home robot for intelligent surveillance...
-

An Emerging Technology: Nanorobotics
Nanorobotics is an emerging technology field creating machines or robots whose components...
-

An Overview: The Internet of Medical Things (IoMT)
The Internet of Medical Things (IoMT) is the network of Internet-connected medical devices...
-

The Internet of Things in Agriculture
The Internet of Things (IoT) is about making “dumb” things “smart” by connecting them to each other...
-
3D Integrated Circuits
Three-dimensional (3D) integrated circuits (ICs), which contain multiple layers of active devices, have the potential...
-
Artificial intelligence in self-driving cars
A self-driving car (sometimes called an autonomous car or driverless car) is a vehicle that uses a combination...
-
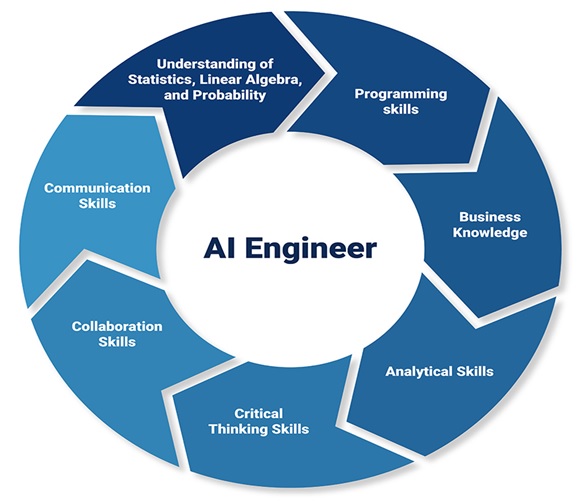
AI Engineering
An artificial intelligence engineer is an individual who works with traditional machine learning techniques...
-

Artificial intelligence in Finance
AI and the finance industry are a match made in heaven. The financial sector relies on accuracy, real-time reporting and processing...
-

Internet of Behaviours (IOB)
Internet of Behaviours (IOB) aims to discuss how data are better understood and used to construct and promote...
-
Machine Learning towards Intelligent Systems
The emergence and continued reliance on the Internet and related technologies has resulted in the generation...
-

Tactile Virtual Reality
Innovative technologies offer more immersive experiences like AR and VR. Virtual Reality immerses the user in a simulated...