
Language Transformers
Natural language solutions require massive language datasets to train processors. This training process deals with issues, like similar-sounding words, that affect the performance of NLP models. Language transformers avoid these by applying self-attention mechanisms to better understand the relationships between sequential elements. Moreover, this type of neural network architecture ensures that the weighted average calculation for each word is unique.[1]
German startup Build & Code uses NLP to process documents in the construction industry. The startup’s solution uses language transformers and a proprietary knowledge graph to automatically compile, understand, and process data. It features automatic documentation matching, search, and filtering as well as smart recommendations. This solution consolidates data from numerous construction documents, such as 3D plans and bills of materials (BOM), and simplifies information delivery to stakeholders.[1]
Birch.AI is a US-based startup that specializes in AI-based automation of call center operations. The startup’s solution utilizes transformer-based NLPs with models specifically built to understand complex, high-compliance conversations. This includes healthcare, insurance, and banking applications. Birch.AI’s proprietary end-to-end pipeline uses speech-to-text during conversations. It also generates a summary and applies semantic analysis to gain insights from customers. The startup’s solution finds applications in challenging customer service areas such as insurance claims, debt recovery, and more.[1]

Figure .1 Language Transformers
Figure 1 shows Language transformers are a type of deep learning model that is specifically designed for natural language processing (NLP) tasks. These models are based on the transformer architecture, which was introduced in the paper "Attention is All You Need" by Vaswani et al. in 2017.
The transformer architecture consists of an encoder and a decoder, each of which contains multiple layers of self-attention and feedforward neural networks. In a language transformer, the encoder processes the input text and generates a set of contextualized embeddings, which are then fed into the decoder to generate the output text. The self-attention mechanism in the transformer architecture allows the model to selectively focus on different parts of the input text, based on the context of the text and the task at hand.
One of the most well-known language transformers is the GPT (Generative Pre-trained Transformer) series developed by OpenAI. The latest version, GPT-3, has over 175 billion parameters and has shown impressive performance on a wide range of NLP tasks, including text completion, translation, and question answering. Other notable language transformers include BERT (Bidirectional Encoder Representations from Transformers), RoBERTa (Robustly Optimized BERT), and XLNet (eXtreme Multi-task Learning with Large-scale Language models).
Language transformers have revolutionized NLP and have become a key tool for many applications, including chatbots, virtual assistants, and sentiment analysis. By leveraging the power of the transformer architecture, language transformers are able to generate more accurate and contextually appropriate responses to user inputs, leading to more natural and effective interactions between humans and machines.
References:
- https://www.startus-insights.com/innovators-guide/natural-language-processing-trends/ - language-transformers
Cite this article:
Janani R (2023), Language Transformers, Anatechmaz, pp.224
Recent Post
-

Object Detection
Object detection, as of one the most fundamental and challenging...
-
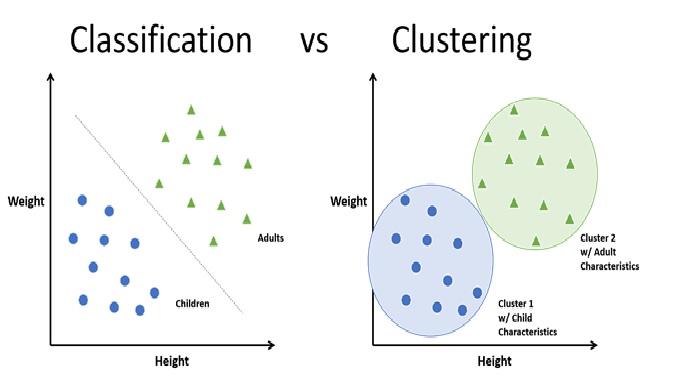
Clustering
Clustering is a technique used in machine learning and data analysis...
-
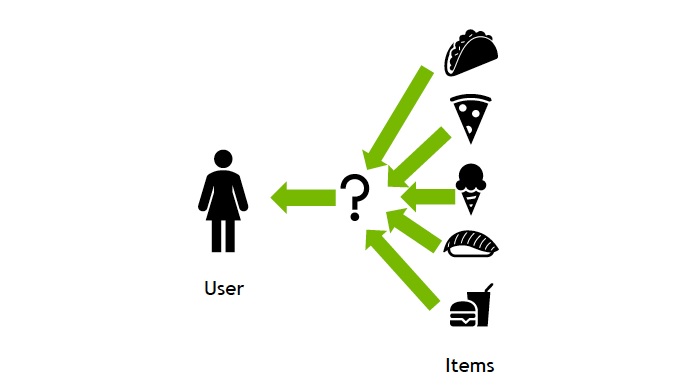
Recommender Systems
Recommender systems are information filtering tools that suggest...
-
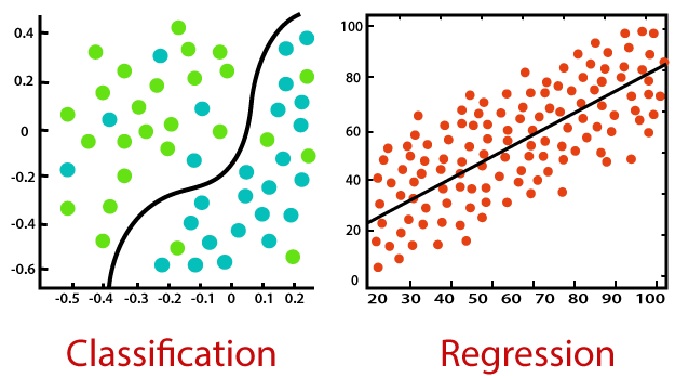
Regression
Regression is a statistical technique used to establish a relationship between...
-

Reinforcement Learning
Reinforcement learning is a type of machine learning where an agent...
-
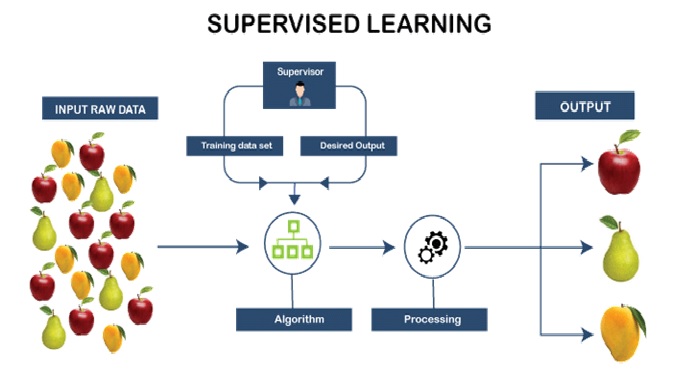
Supervised Learning
Supervised learning is a type of machine learning where the algorithm learns to map ...
-

Multimodal Learning
Multimodal learning involves combining different types of data, such as images...
-
Edge AI
Edge AI, also known as AI at the edge, refers to the deployment of AI algorithms...
-

Edge Analytics
Edge analytics is a type of analytics that involves processing data locally on...
-
YOLO (You Only Look Once)
YOLO (You Only Look Once) is a family of state-of-the-art real-time object...
-

YOLOv5
YOLOv5 is a state-of-the-art object detection algorithm developed...
-
Gamification
Gamification is the process of applying game design elements and principles...
-

Intelligent Tutoring Systems (ITS)
Intelligent Tutoring Systems (ITS) are computer-based systems that use ...
-

Language Transformers
Natural language solutions require massive language datasets to train...
-
Medical Image Analysis
Medical image analysis is the process of analyzing images generated...