
Clustering
Clustering is a technique used in machine learning and data analysis to group similar items or observations together based on their features or attributes. It is an unsupervised learning technique, meaning that it does not require labeled data to learn patterns and groupings.
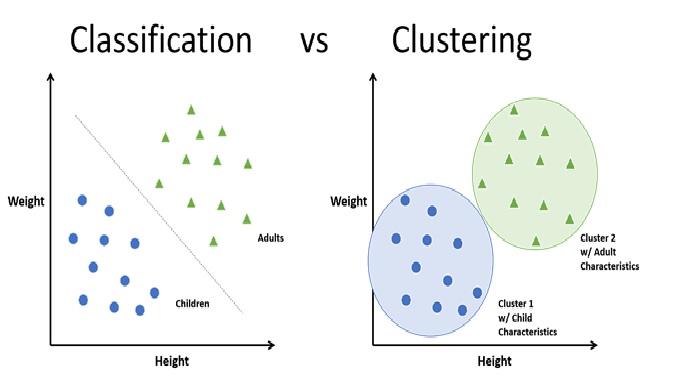
Figure 1. classification vs clustering. [1]
Figure 1 shows classification vs clustering. In clustering, the algorithm looks for similarities among the data points and groups them into clusters based on those similarities. The algorithm tries to maximize the similarity between the items in each cluster and minimize the similarity between items in different clusters.
Clustering has various applications, such as:
Image segmentation: Clustering can be used to segment images into different regions based on their color, texture, or other features.
Customer segmentation: Clustering can be used to group customers based on their buying behavior, demographics, or other attributes.
Anomaly detection: Clustering can be used to detect anomalies in data by identifying items that do not fit well into any of the clusters.
Document clustering: Clustering can be used to group similar documents together based on their content or topic.
There are different clustering algorithms, including K-means clustering, Hierarchical clustering, Density-based clustering, and more. The choice of algorithm depends on the type of data and the specific problem being solved.
References:
- https://www.analyticsvidhya.com/blog/2021/05/what-why-and-how-of-spectral-clustering/
Cite this article:
Hana M (2023), Clustering, AnaTechMaz, pp.212
Recent Post
-

Object Detection
Object detection, as of one the most fundamental and challenging...
-
Clustering
Clustering is a technique used in machine learning and data analysis...
-
Recommender Systems
Recommender systems are information filtering tools that suggest...
-
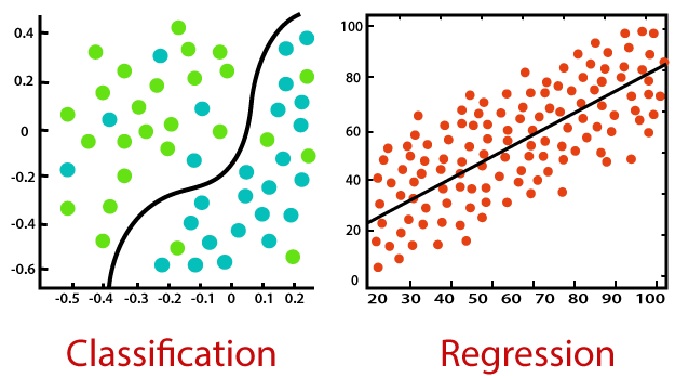
Regression
Regression is a statistical technique used to establish a relationship between...
-

Reinforcement Learning
Reinforcement learning is a type of machine learning where an agent...
-
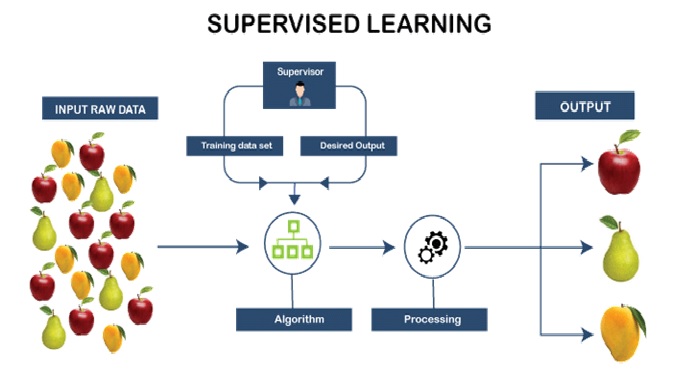
Supervised Learning
Supervised learning is a type of machine learning where the algorithm learns to map ...
-

Multimodal Learning
Multimodal learning involves combining different types of data, such as images...
-
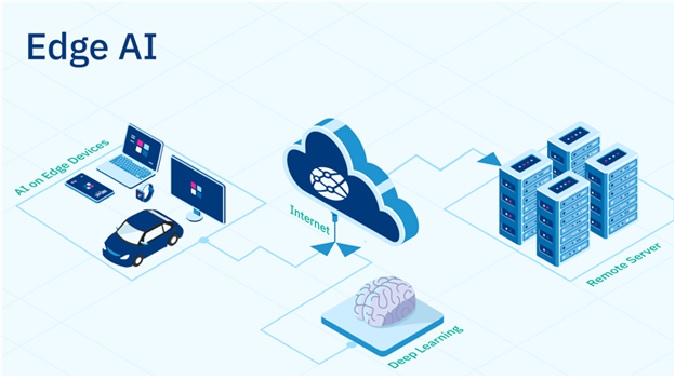
Edge AI
Edge AI, also known as AI at the edge, refers to the deployment of AI algorithms...
-

Edge Analytics
Edge analytics is a type of analytics that involves processing data locally on...
-
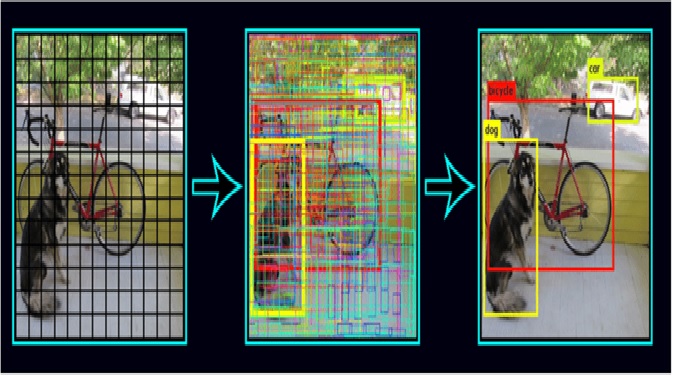
YOLO (You Only Look Once)
YOLO (You Only Look Once) is a family of state-of-the-art real-time object...
-

YOLOv5
YOLOv5 is a state-of-the-art object detection algorithm developed...
-
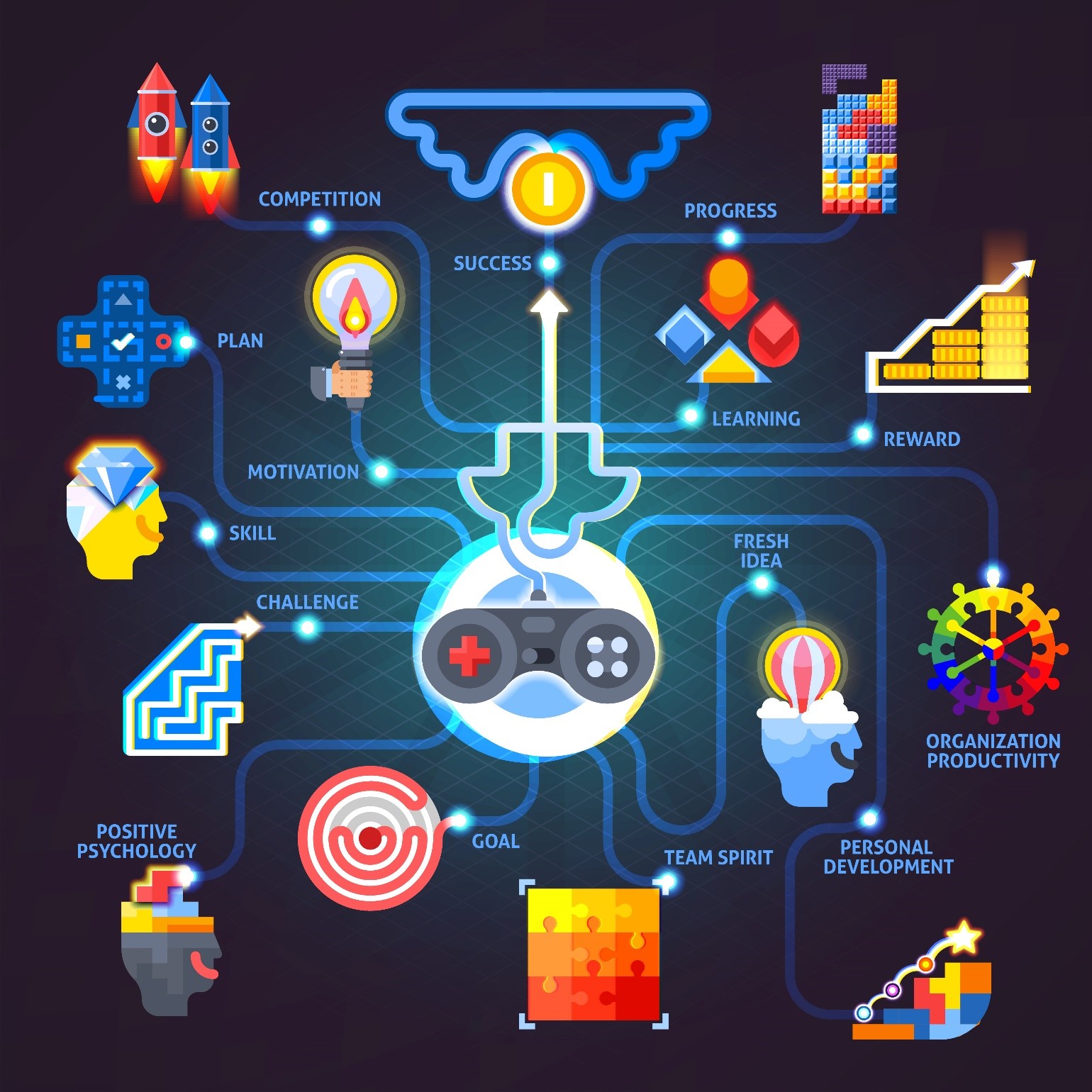
Gamification
Gamification is the process of applying game design elements and principles...
-

Intelligent Tutoring Systems (ITS)
Intelligent Tutoring Systems (ITS) are computer-based systems that use ...
-

Language Transformers
Natural language solutions require massive language datasets to train...
-
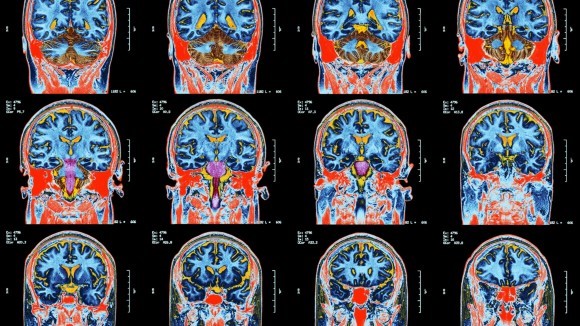
Medical Image Analysis
Medical image analysis is the process of analyzing images generated...