
YOLOv5
YOLOv5 is a state-of-the-art object detection algorithm developed by Ultralytics, which builds on the previous YOLO (You Only Look Once) family of models. YOLOv5 is an improved version of the previous models and offers significantly better performance in terms of speed and accuracy.
Object detection is a computer vision task that involves identifying and localizing objects in an image or video. YOLOv5 is specifically designed for real-time object detection on a wide range of platforms, including mobile devices and embedded systems.

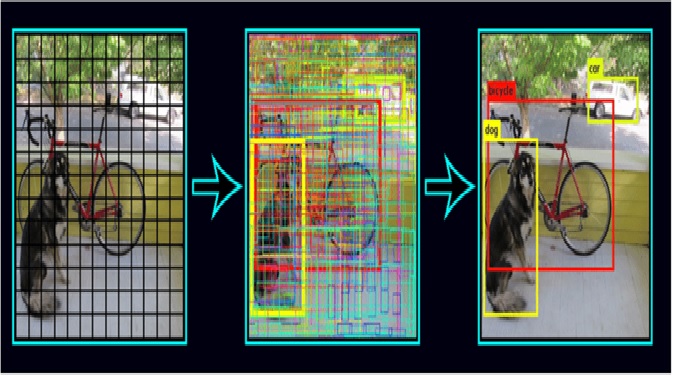
Figure 1. YOLOv5
Figure 1 shows how YOLOv5 works. Here's how YOLOv5 works in detail:
- Backbone network: YOLOv5 uses a neural network architecture that consists of a backbone network and a detection head. The backbone network is responsible for extracting features from the input image. YOLOv5 uses the CSP (Cross-Stage Partial) architecture, which is a variant of the ResNet architecture that reduces computational complexity while maintaining accuracy.
- Feature pyramid network: YOLOv5 uses a feature pyramid network to improve detection at different scales. This network combines features from different levels of the backbone network and produces a set of multi-scale feature maps that are used in the detection head.
- Detection head: The detection head is responsible for performing object detection by predicting the bounding boxes and class probabilities for each detected object. YOLOv5 uses a modified version of the YOLOv3 detection head that includes anchor boxes to improve accuracy.
- Objectness score: For each grid cell, YOLOv5 predicts an objectness score that indicates the likelihood of an object being present in that cell. This score is based on the intersection over union (IoU) between the ground truth bounding boxes and the predicted bounding boxes.
- Bounding box prediction: For each grid cell with a high objectness score, YOLOv5 predicts a bounding box that encloses the object. Each bounding box is represented by four coordinates (x, y, width, height) relative to the grid cell.
- Class prediction: For each bounding box, YOLOv5 predicts the probability that it belongs to each class of objects that the algorithm has been trained to detect.
- Non-maximum suppression: The final step of YOLOv5 involves applying non-maximum suppression to the set of predicted bounding boxes. This removes duplicate detections of the same object and keeps only the most confident detection.
Compared to earlier versions of YOLO, YOLOv5 offers several improvements, including a smaller model size, faster inference speed, and improved accuracy. The model achieves state-of-the-art results on several benchmarks, including the COCO dataset.
YOLOv5 has many practical applications, including in fields such as self-driving cars, robotics, surveillance, and augmented reality. Its fast inference speed and high accuracy make it a popular choice for real-time object detection tasks, where fast and reliable detection is essential.
References:
- https://deci.ai/blog/yolov6-vs-yolov5-vs-yolox/
Cite this article:
Hana M (2023), YOLOv5, AnaTechMaz, pp.221
Recent Post
-

Object Detection
Object detection, as of one the most fundamental and challenging...
-
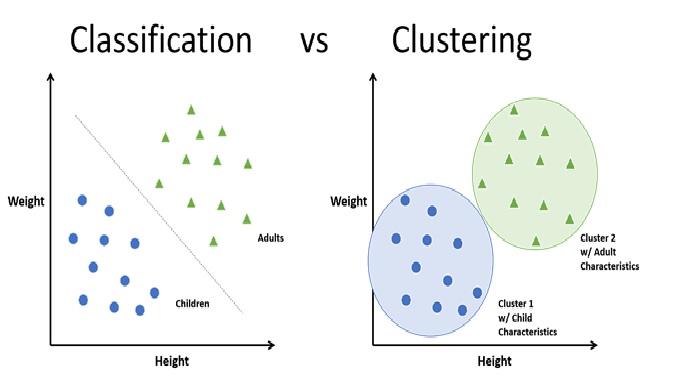
Clustering
Clustering is a technique used in machine learning and data analysis...
-
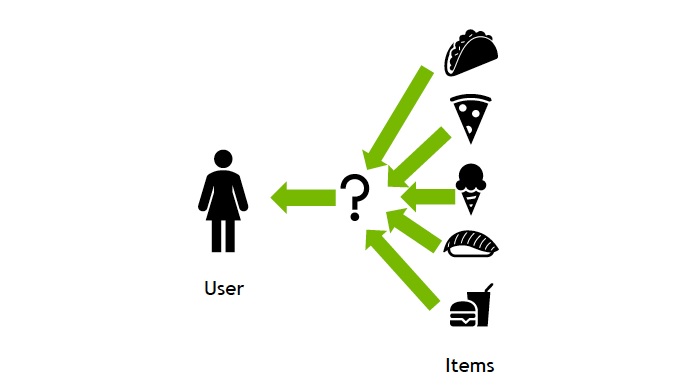
Recommender Systems
Recommender systems are information filtering tools that suggest...
-
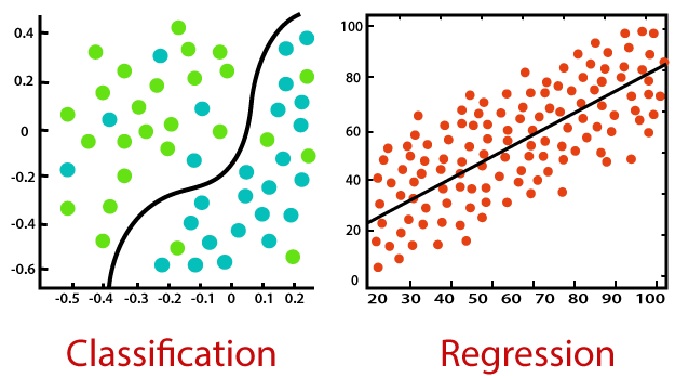
Regression
Regression is a statistical technique used to establish a relationship between...
-

Reinforcement Learning
Reinforcement learning is a type of machine learning where an agent...
-
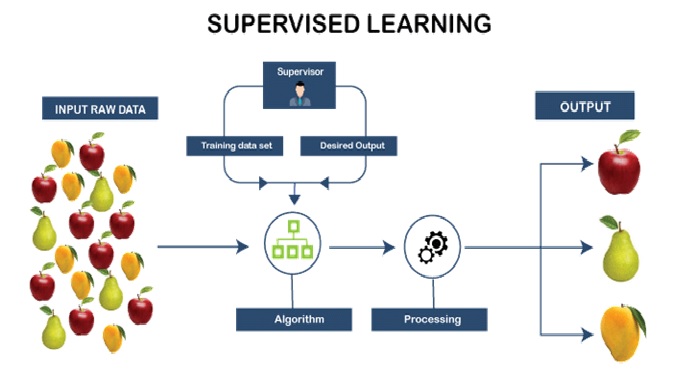
Supervised Learning
Supervised learning is a type of machine learning where the algorithm learns to map ...
-

Multimodal Learning
Multimodal learning involves combining different types of data, such as images...
-
Edge AI
Edge AI, also known as AI at the edge, refers to the deployment of AI algorithms...
-

Edge Analytics
Edge analytics is a type of analytics that involves processing data locally on...
-
YOLO (You Only Look Once)
YOLO (You Only Look Once) is a family of state-of-the-art real-time object...
-
YOLOv5
YOLOv5 is a state-of-the-art object detection algorithm developed...
-
Gamification
Gamification is the process of applying game design elements and principles...
-

Intelligent Tutoring Systems (ITS)
Intelligent Tutoring Systems (ITS) are computer-based systems that use ...
-

Language Transformers
Natural language solutions require massive language datasets to train...
-
Medical Image Analysis
Medical image analysis is the process of analyzing images generated...