
Supervised Learning
Supervised learning is a type of machine learning where the algorithm learns to map inputs to outputs based on labeled examples. The term "supervised" refers to the fact that the algorithm is trained on a labeled dataset where the correct output is provided for each input.
The goal of supervised learning is to learn a mapping function that can accurately predict the output for new, unseen inputs. This is done by minimizing a loss function that measures the difference between the predicted output and the true output for each example in the training dataset.
Supervised learning is widely used in a variety of applications, including image recognition, natural language processing, and speech recognition. Some popular algorithms in supervised learning include linear regression, logistic regression, decision trees, random forests, and neural networks.
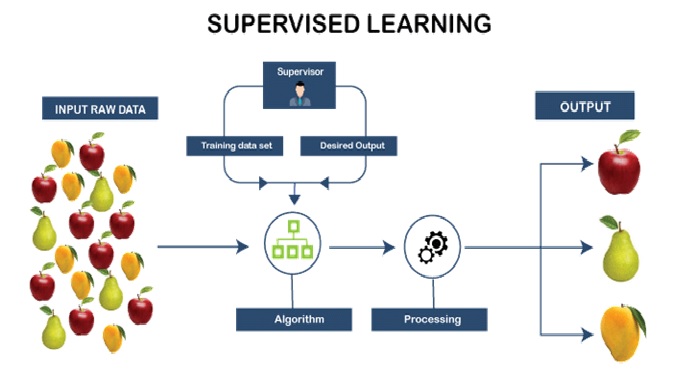
Figure 1. supervised learning.
Figure 1 shows supervised learning.
Supervised Learning Algorithms
Various algorithms and computations techniques are used in supervised machine learning processes. Below are brief explanations of some of the most commonly used learning methods, typically calculated through use of programs like R or Python:
Neural networks: Primarily leveraged for deep learning algorithms, neural networks process training data by mimicking the interconnectivity of the human brain through layers of nodes. Each node is made up of inputs, weights, a bias (or threshold), and an output. If that output value exceeds a given threshold, it “fires” or activates the node, passing data to the next layer in the network. Neural networks learn this mapping function through supervised learning, adjusting based on the loss function through the process of gradient descent. When the cost function is at or near zero, we can be confident in the model’s accuracy to yield the correct answer. [1]
Naive bayes: Naive Bayes is classification approach that adopts the principle of class conditional independence from the Bayes Theorem. This means that the presence of one feature does not impact the presence of another in the probability of a given outcome, and each predictor has an equal effect on that result. There are three types of Naïve Bayes classifiers: Multinomial Naïve Bayes, Bernoulli Naïve Bayes, and Gaussian Naïve Bayes. This technique is primarily used in text classification, spam identification, and recommendation systems. [1]
Linear regression: Linear regression is used to identify the relationship between a dependent variable and one or more independent variables and is typically leveraged to make predictions about future outcomes. When there is only one independent variable and one dependent variable, it is known as simple linear regression. As the number of independent variables increases, it is referred to as multiple linear regression. For each type of linear regression, it seeks to plot a line of best fit, which is calculated through the method of least squares. However, unlike other regression models, this line is straight when plotted on a graph. [1]
Logistic regression: While linear regression is leveraged when dependent variables are continuous, logistic regression is selected when the dependent variable is categorical, meaning they have binary outputs, such as "true" and "false" or "yes" and "no." While both regression models seek to understand relationships between data inputs, logistic regression is mainly used to solve binary classification problems, such as spam identification. [1]
Support vector machines (SVM): A support vector machine is a popular supervised learning model developed by Vladimir Vapnik, used for both data classification and regression. That said, it is typically leveraged for classification problems, constructing a hyperplane where the distance between two classes of data points is at its maximum. This hyperplane is known as the decision boundary, separating the classes of data points (e.g., oranges vs. apples) on either side of the plane. [1]
K-nearest neighbor: K-nearest neighbor, also known as the KNN algorithm, is a non-parametric algorithm that classifies data points based on their proximity and association to other available data. This algorithm assumes that similar data points can be found near each other. As a result, it seeks to calculate the distance between data points, usually through Euclidean distance, and then it assigns a category based on the most frequent category or average. Its ease of use and low calculation time make it a preferred algorithm by data scientists, but as the test dataset grows, the processing time lengthens, making it less appealing for classification tasks. KNN is typically used for recommendation engines and image recognition. [1]
Random forest: Random forest is another flexible supervised machine learning algorithm used for both classification and regression purposes. The "forest" references a collection of uncorrelated decision trees, which are then merged together to reduce variance and create more accurate data predictions. [1]
In supervised learning, the quality of the labeled data is crucial to the performance of the algorithm. If the labeled data is noisy or incorrect, the algorithm may not be able to learn an accurate mapping function. Therefore, it is important to have high-quality labeled data for supervised learning tasks.
References:
- https://www.ibm.com/topics/supervised-learning
- https://www.tutorialandexample.com/supervised-machine-learning
Cite this article:
Hana M (2023), Supervised Learning, AnaTechMaz, pp.216
Recent Post
-

Object Detection
Object detection, as of one the most fundamental and challenging...
-
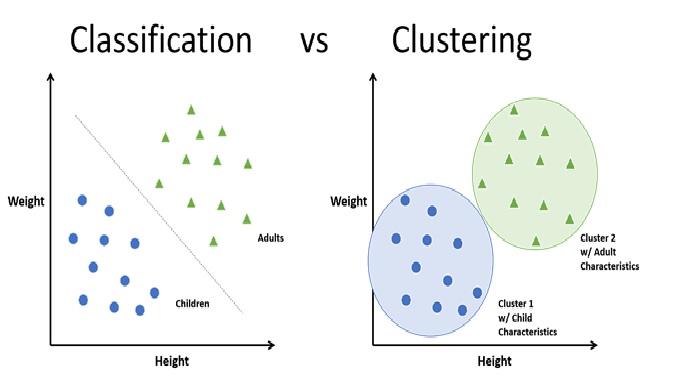
Clustering
Clustering is a technique used in machine learning and data analysis...
-
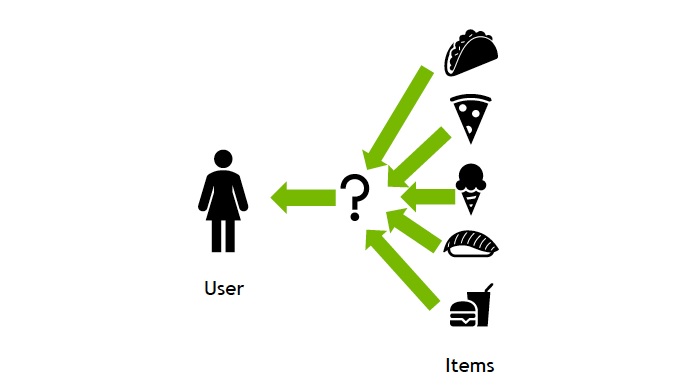
Recommender Systems
Recommender systems are information filtering tools that suggest...
-
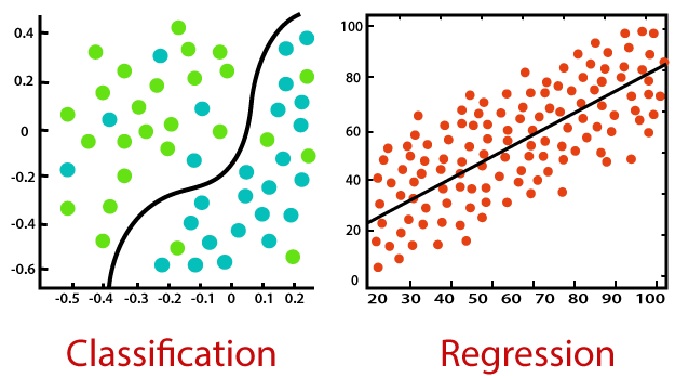
Regression
Regression is a statistical technique used to establish a relationship between...
-

Reinforcement Learning
Reinforcement learning is a type of machine learning where an agent...
-
Supervised Learning
Supervised learning is a type of machine learning where the algorithm learns to map ...
-

Multimodal Learning
Multimodal learning involves combining different types of data, such as images...
-
Edge AI
Edge AI, also known as AI at the edge, refers to the deployment of AI algorithms...
-

Edge Analytics
Edge analytics is a type of analytics that involves processing data locally on...
-
YOLO (You Only Look Once)
YOLO (You Only Look Once) is a family of state-of-the-art real-time object...
-

YOLOv5
YOLOv5 is a state-of-the-art object detection algorithm developed...
-
Gamification
Gamification is the process of applying game design elements and principles...
-

Intelligent Tutoring Systems (ITS)
Intelligent Tutoring Systems (ITS) are computer-based systems that use ...
-

Language Transformers
Natural language solutions require massive language datasets to train...
-
Medical Image Analysis
Medical image analysis is the process of analyzing images generated...