
Hadoop
Apache Hadoop is an open-source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data. Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly [1].
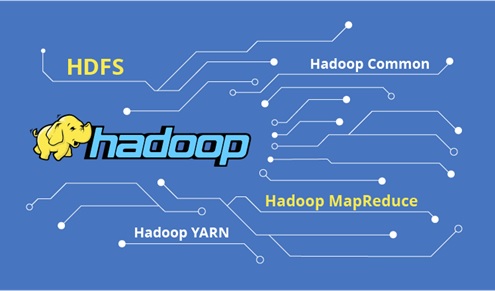
Figure 1: Ecosystem of Hadoop
Hadoop consists of four main modules as shown in figure 1:
- Hadoop Distributed File System (HDFS) – A distributed file system that runs on standard or low-end hardware. HDFS provides better data throughput than traditional file systems, in addition to high fault tolerance and native support of large datasets.
- Yet Another Resource Negotiator (YARN) – Manages and monitors cluster nodes and resource usage. It schedules jobs and tasks.
- MapReduce – A framework that helps programs do the parallel computation on data. The map task takes input data and converts it into a dataset that can be computed in key value pairs. The output of the map task is consumed by reduce tasks to aggregate output and provide the desired result.
- Hadoop Common – Provides common Java libraries that can be used across all modules.
The Hadoop ecosystem has grown significantly over the years due to its extensibility. Today, the Hadoop ecosystem includes many tools and [2] applications to help collect, store, process, analyze, and manage big data. Some of the most popular applications are:
- Spark – An open source, distributed processing system commonly used for big data workloads. Apache Spark uses in-memory caching and optimized execution for fast performance, and it supports general batch processing, streaming analytics, machine learning, graph databases, and ad hoc queries.
- Presto – An open source, distributed SQL query engine optimized for low-latency, ad-hoc analysis of data. It supports the ANSI SQL standard, including complex queries, aggregations, joins, and window functions. Presto can process data from multiple data sources including the Hadoop Distributed File System (HDFS) and Amazon S3.
- Hive – Allows users to leverage Hadoop MapReduce using a SQL interface, enabling analytics at a massive scale, in addition to distributed and fault-tolerant data warehousing.
- HBase – An open source, non-relational, versioned database that runs on top of Amazon S3 (using EMRFS) or the Hadoop Distributed File System (HDFS). HBase is a massively scalable, distributed big data store built for random, strictly consistent, real-time access for tables with billions of rows and millions of columns.
- Zeppelin – An interactive notebook that enables interactive data exploration.
The Impact of Hadoop
Hadoop was a major development in the big data space. In fact, it is credited with being the foundation for the modern cloud data lake. Hadoop democratized computing power and made it possible for companies to analyze and query big data sets in a scalable manner using free, opensource software and inexpensive, off-the-shelf hardware. [3] This was a significant development because it offered a viable alternative to the proprietary data warehouse (DW) solutions and closed data formats that had ruled the day until then. With the introduction of Hadoop, organizations quickly had access to the ability to store and process huge amounts of data, increased computing power, fault tolerance, flexibility in data management, lower costs compared to DWs, and greater scalability - just keep on adding more nodes. Ultimately, Hadoop paved the way for future developments in big data analytics, like the introduction of Apache Spark™.
The Impact of Hadoop
- Scalability— Unlike traditional systems that limit data storage, Hadoop is scalable as it operates in a distributed environment. [4] This allowed data architects to build early data lakes on Hadoop. Learn more about the history and evolution of data lakes.
- Resilience— The Hadoop Distributed File System (HDFS) is fundamentally resilient. Data stored on any node of a Hadoop cluster is also replicated on other nodes of the cluster to prepare for the possibility of hardware or software failures. This intentionally redundant design ensures fault tolerance. If one node goes down, there is always a backup of the data available in the cluster.
- Flexibility— unlike traditional relational database management systems, when working with Hadoop, you can store data in any format, including semi-structured or unstructured formats. Hadoop enables businesses to easily access new data sources and tap into different types of data.
The Hadoop ecosystem
The Hadoop framework, built by the Apache Software Foundation, [5] includes:
- Hadoop Common: The common utilities and libraries that support the other Hadoop modules. Also known as Hadoop Core.
- Hadoop HDFS (Hadoop Distributed File System): A distributed file system for storing application data on commodity hardware. It provides high-throughput access to data and high fault tolerance. The HDFS architecture features a NameNode to manage the file system namespace and file access and multiple DataNodes to manage data storage.
- Hadoop YARN: A framework for managing cluster resources and scheduling jobs. YARN stands for Yet Another Resource Negotiator. It supports more workloads, such as interactive SQL, advanced modeling and real-time streaming.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
- Hadoop Ozone: A scalable, redundant and distributed object store designed for big data applications.
References:
- https://aws.amazon.com/emr/details/hadoop/what-is-hadoop/
- https://databricks.com/glossary/hadoop
- https://www.cloudera.com/products/open-source/apache-hadoop.html
- https://www.ibm.com/analytics/hadoop
- https://www.sas.com/en_in/insights/big-data/hadoop.html
Cite this article:
D. Vinotha (2021), Hadoop pp. 5
Recent Post
-

Data Science in Modern Agriculture
Agriculture is the backbone of the world economy, but the industry currently needs more support than any other...
-

Security Trends in Data Centers in 2021
Data center security is an ongoing challenge for virtually every modern organization.
-

Database Architecture
A Database Architecture is a representation of DBMS design. It helps to design, develop, implement, and maintain the database management system.
-
Big Data Analytics
Big data analytics is the use of advanced analytic techniques against very large, diverse data sets that include structured
-
Hadoop
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data.
-

Lifecycle: Big Data Analytics
Big Data analysis differs from traditional data analysis primarily due to the volume, velocity and variety characteristics of the data being processes.
-
Angular vs Node JS
Angular is a platform for developing single-page applications with the use of TypeScript and HTML....
-
Full Stack Development
Full stack development: It refers to the development of both front end (client side) and back end (server side) portions of web application...
-
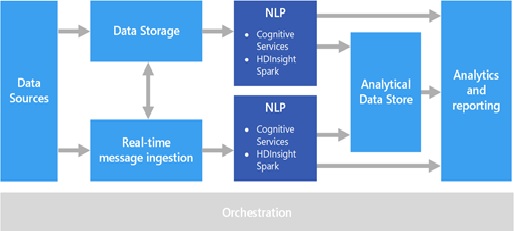
Methods of Natural Language Processing
Natural language processing strives to build machines that understand and respond to text or voice data...
-

A Deep Study of Data science
Data science is a deep study of the massive amount of data, which involves extracting meaningful insights from raw...
-

Benefits of Data visualization
Data visualization is the graphical representation...
-
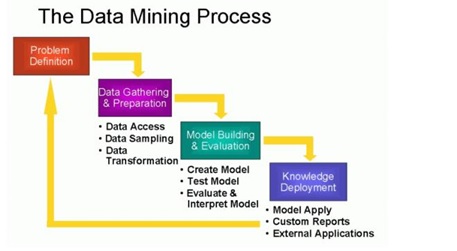
The Process of Data Mining
Data mining is more than just extracting or mining data...
-
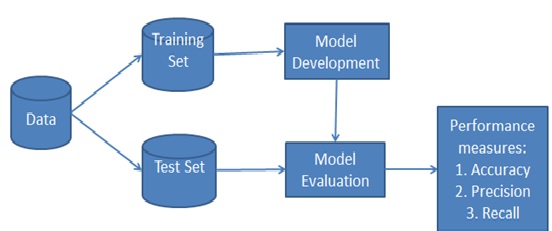
Benefits of Naive Bayes
Naive Bayes falls under the umbrella of supervised machine learning algorithms that are primarily used for classification...
-

Functions Of Data Warehouse Modernization
We’re living in times where big data and analytics are driving all business decisions and traditional...
-
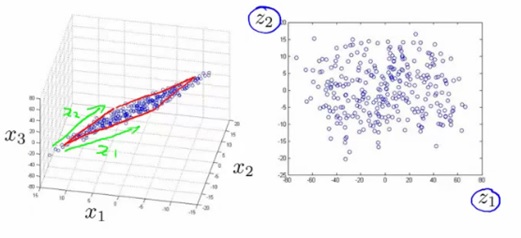
Techniques Of Dimensionality Reduction Method
The number of input features, variables, or columns present in a given...