
Benefits of Naive Bayes
Naive Bayes falls under the umbrella of supervised machine learning algorithms that are primarily used for classification. In this context, "supervised" tells us that the algorithm is trained with both input features and categorical outputs (i.e., the data includes the correct desired output for each point, which the algorithm should predict).
But why is the algorithm called naïve This is because the classifier assumes that the input features that go into the model are independent of each other. Hence, changing one input feature won’t affect any of the others. It's [1] therefore naive in the sense that this assumption may or may not be true, and it most probably isn't.
We’ll discuss the naiveness of this algorithm in detail in the Working of Naive Bayes Algorithm section. Before that, let’s briefly look at why this algorithm is simple, yet powerful, and easy to implement. One of the significant advantages of Naive Bayes is that it uses a probabilistic approach; all the computations are done on the fly in real time, and outputs are generated instantaneously. When handling large amounts of data, this gives Naive Bayes an upper hand over traditional classification algorithms like SVMs and Ensemble techniques.
Let’s get started by getting a hang of the theory essential to understanding Naive Bayes.
Introduction to Naive Bayes: A Probability-Based Classification Algorithm
- Introduction to Naive Bayes Algorithm. Naive Bayes falls under the umbrella of supervised machine learning algorithms.
- Probability, Conditional Probability, and Bayes Theorem. Probability is the foundation upon which Naive Bayes has been.
- Working of the Naive Bayes Algorithm. The Bayes Rule provides the formula to compute the probability of output (Y) given.
- Applications. Real-time prediction: Naive Bayes is an eager learning classifier
- Naive Bayes Assumption [2] and Why
- Theoretically, it is not hard to find P(X|Y). However, it is much harder in reality as the number of features grows.
- Estimate Join Distribution requires more data
- Having this amount of parameters in the model is impractical. To solve this problem, a naive assumption is made. We pretend all features are independent.
Naive Bayes Classification
Naive Bayes classifiers are linear classifiers that are known for being simple yet very efficient. The probabilistic model of naive Bayes classifiers is based on Bayes’ theorem, and the adjective naive comes from the assumption that the features in a dataset are mutually independent. In practice, the independence assumption is often violated, but naive Bayes classifiers still tend to perform very well under this unrealistic assumption. Especially for small sample sizes, naive Bayes classifiers can outperform the more powerful alternatives.
Being relatively robust, easy to implement, fast, and accurate, naive Bayes classifiers are used in many different fields. Some examples include the diagnosis of diseases and making decisions about treatment processes, the classification of RNA sequences in taxonomic studiand spam filtering in e-mail clients.
However, strong violations of the independence assumptions and non-linear classification problems can lead to very poor performances of naive Bayes classifiers.We have to keep in mind that the type of data and the type problem to be solved dictate which classification model we want [3] to choose. In practice, it is always recommended to compare different classification models on the particular dataset and consider the prediction performances as well as computational efficiency figure1shown given below.
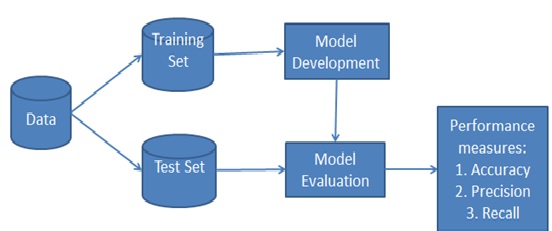
Figure1: Naïve Bayes
- Removing stopwords These are common words that don’t really add anything to the classification, such as a, able, either, else, ever and so on. So for our purposes, The election was over would be election over and a very close game would be very close game.
- Lemmatizing words This is grouping together different inflections of the same word. So election, elections, elected, and so on would be grouped together and counted as more appearances of the same word.
- Using n-grams Instead of counting single words as we did here, we could count sequences of words, like clean match and close election.
References:
- https://www.geeksforgeeks.org/naive-bayes-classifiers
- https://towardsdatascience.com/naive-bayes-explained-9d2b96f4a9c0
- https://blog.paperspace.com/introduction-to-naive-bayes
Cite this article:
S. Nandhinidwaraka (2021) Benefits of Naïve Bayes, pp. 13
Recent Post
-

Data Science in Modern Agriculture
Agriculture is the backbone of the world economy, but the industry currently needs more support than any other...
-

Security Trends in Data Centers in 2021
Data center security is an ongoing challenge for virtually every modern organization.
-

Database Architecture
A Database Architecture is a representation of DBMS design. It helps to design, develop, implement, and maintain the database management system.
-
Big Data Analytics
Big data analytics is the use of advanced analytic techniques against very large, diverse data sets that include structured
-
Hadoop
Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data.
-

Lifecycle: Big Data Analytics
Big Data analysis differs from traditional data analysis primarily due to the volume, velocity and variety characteristics of the data being processes.
-
Angular vs Node JS
Angular is a platform for developing single-page applications with the use of TypeScript and HTML....
-
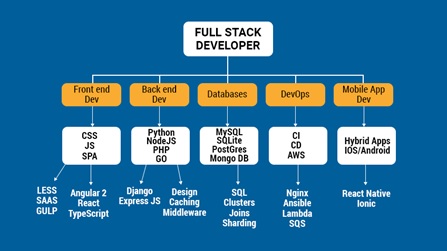
Full Stack Development
Full stack development: It refers to the development of both front end (client side) and back end (server side) portions of web application...
-
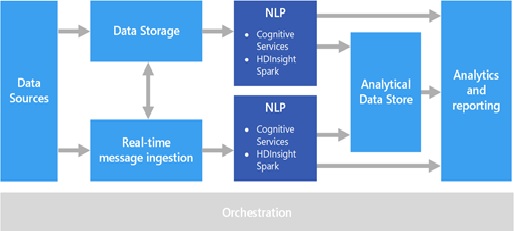
Methods of Natural Language Processing
Natural language processing strives to build machines that understand and respond to text or voice data...
-

A Deep Study of Data science
Data science is a deep study of the massive amount of data, which involves extracting meaningful insights from raw...
-

Benefits of Data visualization
Data visualization is the graphical representation...
-
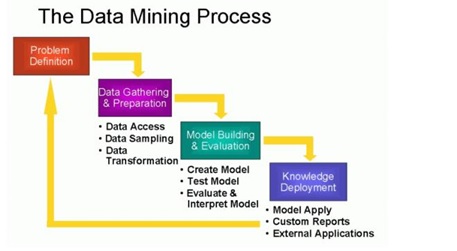
The Process of Data Mining
Data mining is more than just extracting or mining data...
-
Benefits of Naive Bayes
Naive Bayes falls under the umbrella of supervised machine learning algorithms that are primarily used for classification...
-

Functions Of Data Warehouse Modernization
We’re living in times where big data and analytics are driving all business decisions and traditional...
-
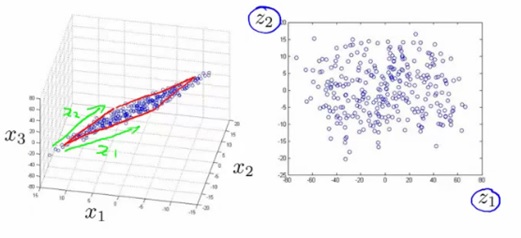
Techniques Of Dimensionality Reduction Method
The number of input features, variables, or columns present in a given...