
Characteristics of Data Lake
A data lake is a storage repository that holds a vast amount of raw data in its native format until it is needed for analytics applications. While a traditional data warehouse stores data in hierarchical dimensions and tables, a data lake uses a flat architecture to store data, primarily in files or object storage.[1]
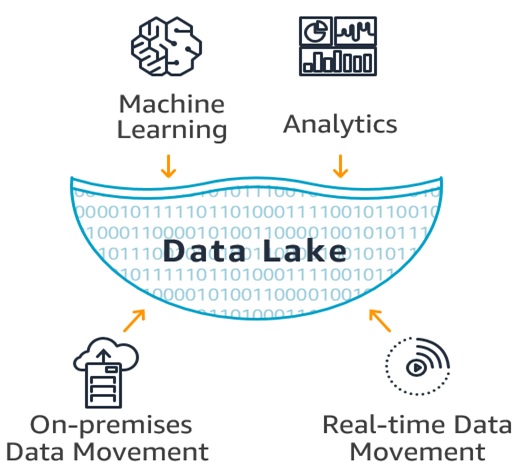
Figure 1. Data lake is the centre location for storage
Figure 1 shows a data lake is a central location that holds a large amount of data in its native, raw format. Compared to a hierarchical data warehouse, which stores data in files or folders, a data lake uses a flat architecture and object storage to store the data. Object storage stores data with metadata tags and a unique identifier, which makes it easier to locate and retrieve data across regions, and improves performance. By leveraging inexpensive object storage and open formats, data lakes enable many applications to take advantage of the data.[2]
Important data lake characteristics
Beyond its core architecture, a data lake must also include some key features:
- Diverse interfaces, APIs, and endpoints for uploading, accessing, and moving data. These are important because they support the data lake’s extreme variety of possible use cases.
- Sophisticated access control mechanisms. Data owners must be able to set permissions for keeping data secure and private when and where it needs to be. Access control, encryption, and network security features are critical for data governance.
- Search and cataloguing features. Without generic methods for organizing and locating huge amounts of diverse data, data lakes fail to be maximally available and useful. These features might include optimized key-value storage, metadata, tagging, or tools for collecting and classifying subsets of all objects.
- Support for the construction of or connection to processing and analytics layers. Analysts, data scientists, machine learning engineers, and decision-makers all derive the greatest benefit from centralized, fully available data, so the lake must support their various processing, transformation, aggregation, and analytical needs.[3]
Building a lake house with Delta Lake
To build a successful lake house, organizations have turned to Delta Lake, an open format data management and governance layer that combines the best of both data lakes and data warehouses. Across industries, enterprises are leveraging Delta Lake to power collaboration by providing a reliable, single source of truth. By delivering quality, reliability, security and performance on your data lake — for both streaming and batch operations — Delta Lake eliminates data silos and makes analytics accessible across the enterprise. With Delta Lake, customers can build a cost-efficient, highly scalable lake house that eliminates data silos and provides self-serving analytics to end-users.[2]
References:
- https://searchdatamanagement.techtarget.com/definition/data-lake
- https://databricks.com/discover/data-lakes/introduction
- https://www.stitchdata.com/resources/what-is-data-lake/
Cite this article:
Thanusri swetha J (2021), Characteristics of data lake, Anatechmaz, pp. 19
Recent Post
-

Augmented Analytics in Data Science
Augmented analytics is the use of enabling technologies such as machine learning and AI to assist...
-
Automatic Identification and Data Capture (AIDC)
Data discovery has increased its impact in the last year. A survey conducted by the Business Application...
-
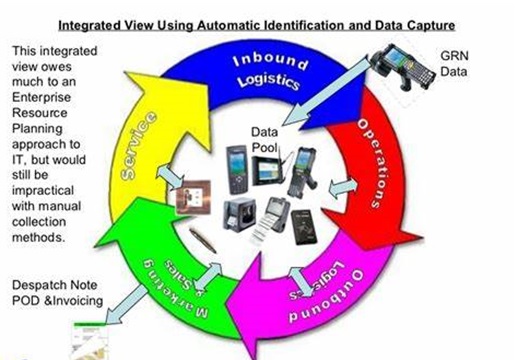
Automatic Identification of Data Collection
Automatic identification and data collection (also called AIDC, Auto ID, automatic data capture...
-
Characteristics of Data Lake
A data lake is a storage repository that holds a vast amount of raw data in its native format until it is needed for analytics...
-
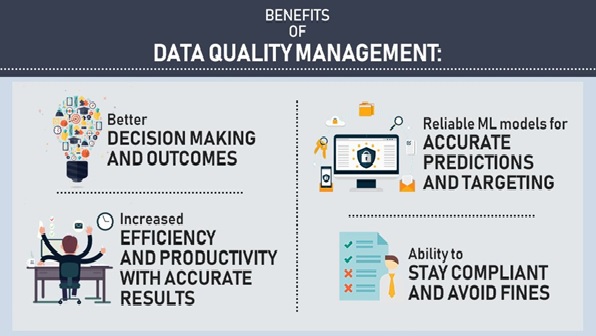
Data Quality Management (DQM)
Data is the driving force of every organization in the modern world. As organizations continue to collect more...
-

Embedded Analytics
When data analytics occurs within a user’s natural workflow, embedded analytics is the name of the game...
-
Graph Analytics in Data Science
Graph Data Science is a science-driven approach to gain knowledge from the relationships and structures in data...
-
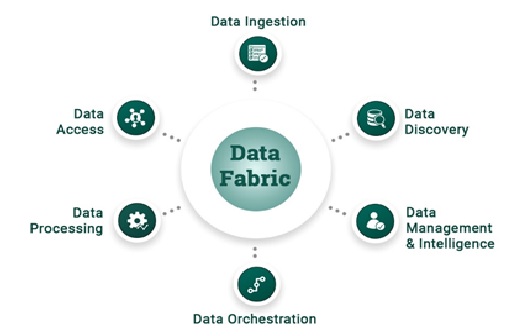
The Capabilities of Data Fabric
Gartner defines data fabric as a design concept that serves as an integrated layer (fabric) of data and connecting processes...
-
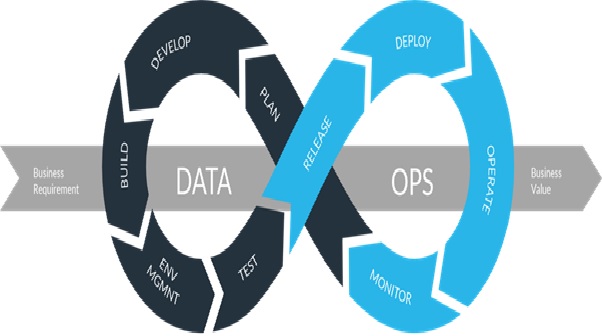
The Future of DataOps
DataOps (data operations) is an agile, process-oriented methodology for developing and delivering analytics...
-

The Future of Encryption
Data encryption is the process by which digital data is translated into a complex code using encryption algorithms...
-
The Real Time Data Analytics
Streaming data or real-time data is dynamic data that is continuously generated from a variety of sources like sensors...
-

Data Discovery/Visualization
Data discovery has increased its impact in the last year. A survey conducted by the Business Application Research Center...
-
Benefits and Stages of Data Warehouse Modernization
Data warehousing is a technology that aggregates structured data from one or more sources...
-
Data Governance Tools (DG)
Data governance (DG) is the process of managing the availability, usability, integrity and security of the data in enterprise systems...
-
The Basic of Data Wrapper
Patterns and frameworks form an integral component of software engineering. A wrapper pattern is a class with a special interface...