
Parallella
The Parallella platform is an open source, energy efficient, high performance, credit-card-sized computer based on the Epiphany multicore chips developed by Adapteva. This affordable platform is designed for developing [1] and implementing high performance, parallel processing applications developed to take advantage of the on-board Epiphany chip.
Brief Introduction to Parallella
- Parallella Presented By: Somnath Mazumdar University of Siena, Italy.
- Outline This Presentation was held on 10th Dec 2014 Place: Ericsson Research Lab, Lund Sweden This work is licensed.
- Outline Introduction Architecture System View Programming Conclusion Outline.
- Genesis Influenced by Open-Source Hardware Design projects: Arduino Beaglebone Inspired by: Raspberry Pi Zedboard
- In News “Smallest Supercomputer in the World” Adapteva A Launched at ISC'14
Parallella Memory Details
This page is meant for people who want to understand the different types of memory that are available on the Parallella. It does not contain required knowledge for those who only want to use the Epiphany BSP library.
This page tries to take away any confusion about the different types of memory available for the Epiphany cores and explain the terminology [2] that is being used in the community.
An Epiphany core is sometimes referred to as a mesh node since the network of cores is called a mesh network shown in a figure1.
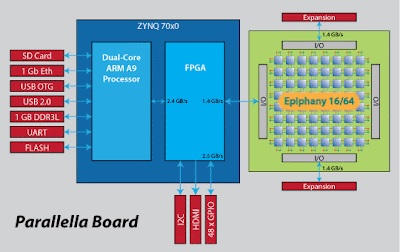
Figure 1. parallella Board
Memory Types
The Epiphany cores have access to two types of memory. Both types can be accessed directly (e.g., by dereferencing a pointer). Here we will give a short overview of these two types. For more details see the Epiphany architecture reference.
All addresses shown below are the ones used by the Epiphany cores. They cannot be used directly by the ARM processor.
Internal memory
- Size: 32KB (0x8000) per core
- Location in address space:
- 0x00000000 - 0x00007fff when a core is referring to its own memory
- 0x???00000 - 0x???07fff when referring to the memory of any other core (or itself). The ??? indicates the Epiphany core, using 6 bits for the row and 6 bits for the column.
Terminology:
- Internal memory
- eCore memory
- SRAM or Static RAM. Not to be confused with Shared RAM.
Usage:
- Program code, starting at lower addresses
- Program data (global variables), starting at lower addresses after code
- Stack (local variables), starting at 0x8000 expanding downwards
External memory
- Size: 32 MB (0x02000000) shared over all cores
- Location in address space
- 0x8e000000 - 0x8fffffff
Terminology:
- External memory
- Shared memory
- DRAM or Dynamic RAM
- SDRAM or Shared DRAM
DMA Engine
Each Epiphany processor contains a DMA engine which can be used to transfer data. The advantage of the DMA [3] engine over normal memory access is that the DMA engine is faster and can transfer data while the CPU does other things. There are two DMA channels, meaning that two pairs of source/destination addresses can be set and the CPU can continue while the DMA engine is transfering data. This source and destination addresses can even both be pointing at other cores’ internal memory. To use the DMA engine one can, use the e_dma_xxx functions from the ESDK. When writing EBSP programs you should prefer ebsp_dma_push() to let the EBSP system manage the DMA engine.
Accessing the memory directly from the ARM processor
The EBSP library supports a number of ways to write to the Epiphany cores. If for some reason you want to use the ESDK directly, you can use e_read and e_write ESDK functions in order to write to the internal memory of each core.
To write to external memory, one has to use e_alloc to “allocate” external memory. This function does not actually allocate memory (it is already there), it _only_ gives you a e_mem_t struct that allows you to access the memory with e_read and e_write calls. The offset that you pass to e_alloc will be an offset from 0x8e000000, meaning an offset of 0x01000000 will give you access to the external memory at 0x8e000000 + 0x01000000 = 0x8f000000 (shared_dram) as seen from the Epiphany. Subsequent [4] offsets can then be added on top of this in e_read and e_write calls.
Memory speed
To give an idea of the efficiency of the types of memory, we share here benchmark data that has been taken from https://parallella.org/forums/viewtopic.php?f=23&t=307&sid=773cf3c3fc58f303645cfe0a684965a7
The Rift DK1 was released on March 29, 2013, and uses a 7-inch (18 cm) screen with a significantly lower pixel switching time than the original prototype, reducing latency and motion blur when turning one's head quickly. The pixel fill is also better, reducing the screen door effect and making individual pixels less noticeable. The LCD is brighter and the color depth is 24 bits per pixel.
SRAM = Internal memory
ERAM = External memory
Host -> SRAM: Write speed = 14.62 MBps
Host <- SRAM: Read speed = 17.85 MBps
Host -> ERAM: Write speed = 100.71 MBps
Host <- ERAM: Read speed = 135.42 MBps
Using memory:
Core -> SRAM: Write speed = 504.09 MBps clocks = 9299
Core <- SRAM: Read speed = 115.65 MBps clocks = 40531
Core -> ERAM: Write speed = 142.99 MBps clocks = 32782
Core <- ERAM: Read speed = 4.19 MBps clocks = 1119132
Using DMA:
Core -> SRAM: Write speed = 1949.88 MBps clocks = 2404
Core <- SRAM: Read speed = 480.82 MBps clocks = 9749
Core -> ERAM: Write speed = 493.21 MBps clocks = 9504
Core <- ERAM: Read speed = 154.52 MBps clocks = 30336
The Parallella computer platform is an open source, energy efficient, high performance, credit-card-sized computer based on the Epiphany multicore chips from Adapteva. This affordable platform is designed for developing and implementing high performance, parallel processing. Applications developed [5] to take advantage of the on-board Epiphany parallel processor can achieve unprecedented performance at the lowest power in the industry.
References:
- https://elinux.org/Parallella
- https://elinux.org/Parallella_Software
- https://www.fabtolab.com/parallella-16-board
- https://www.slideshare.net/ambilibaby/parallella-seminar-ppt
- https://markdewing.github.io/blog/posts/introduction-to-parallella
Cite this article:
S. Nandhinidwaraka (2021) Parallella, AnaTechMaz, pp 8
Recent Post
-

Human and Technology Connection
Technology is more than an abstract concept associated with advanced tools and systems used by businesses...
-
Virtual Reality and Augmented Reality
Virtual Reality (VR) is the use of computer technology to create a simulated environment.
-
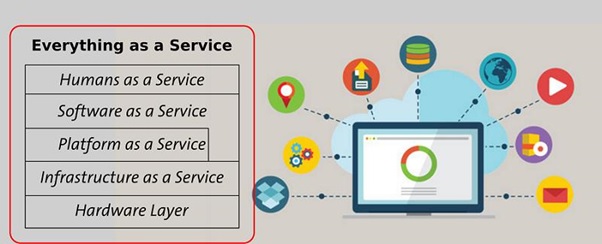
Everything-as-a-Service (XaaS)
Everything-as-a-Service is a term for services and applications that users can access on the Internet upon request.
-
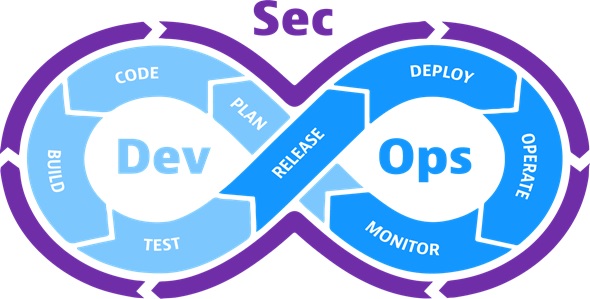
DevSecOps
DevSecOps—short for development, security, and operations—automates the integration of security at every phase of the software development
-
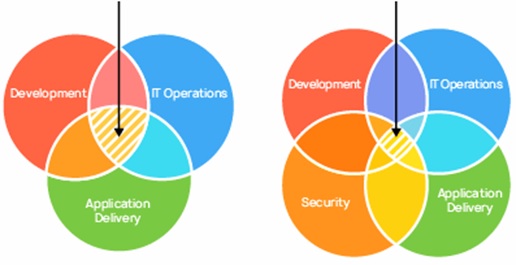
The Difference: DevSecOps vs. DevOps
DevOps isn’t just about development and operations teams.
-

Oculus Rift
An Oculus Rift is a head-mounted display manufactured by Oculus VR. It is a specially designed virtual reality display that makes use of state-of-the-art
-
Parallella
The Parallella platform is an open source, energy efficient, high performance, credit-card-sized computer based on the Epiphany multicore chips developed by Adapteva.
-
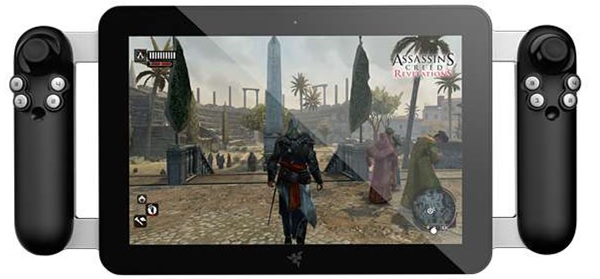
Project Fiona
At the 2012 Consumer Electronics Show, Razer -- a company known for developing computer gaming gear like mice and keyboards
-
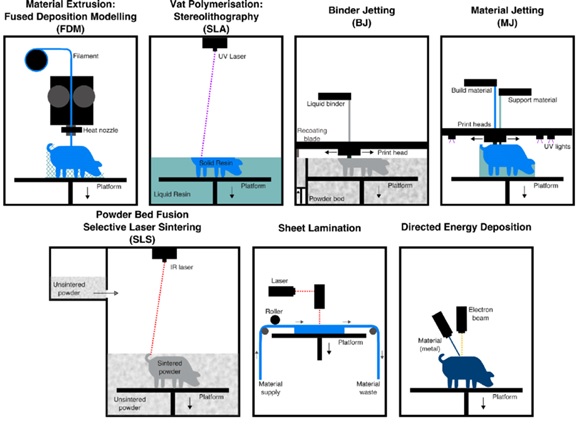
Types of 3D printing
The term 3D printing encompasses several manufacturing technologies that build parts layer-by-layer...
-
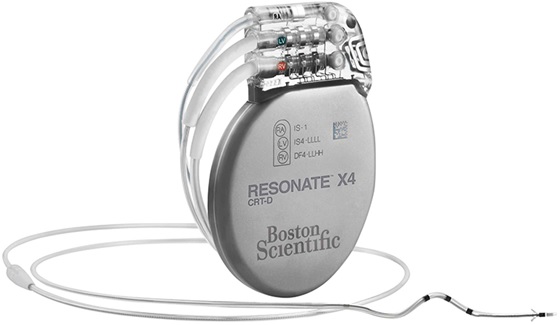
Heart Logic Heart Failure Diagnostic
HeartLogic is a personalized, remote heart failure diagnostic and monitoring solution...
-

Telehealth
The Health Resources Services Administration defines telehealth as the use of electronic information and telecommunications...
-
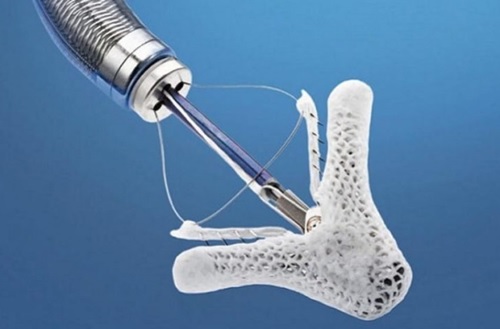
MitraClip: Transcatheter Mitral Valve Repair
MitraClip is the world’s first transcatheter mitral valve repair (TMVr) therapy...
-

The VENOVO Venous Stent System-BD
The VENOVO Venous Stent System is intended to treat a narrowed vein found...
-
LyGenesis develops Organ Regeneration Technology
LyGenesis' lead development asset is liver regeneration, which was the focus of the first two papers. Development...
-
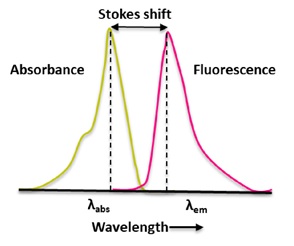
Anti-Stokes Fluorescence Technology
SolCold – Anti-Stokes Fluorescence Technology Israeli startup SolCold develops...