
Researchers Tackle Vanishing Gradients in Deep RNNs with Equilibrium Propagation
Equilibrium Propagation (EP) is emerging as a lower-compute alternative to traditional backpropagation, offering potential for on-chip learning. However, its use in deep networks has been constrained by training challenges. Researchers Jiaqi Lin, Malyaban Bal, and Abhronil Sengupta from The Pennsylvania State University introduce a new EP framework that integrates intermediate error signals, improving information flow and enabling the training of much deeper architectures. Demonstrating state-of-the-art results on image recognition tasks with deep VGG models and datasets like CIFAR-10 and CIFAR-100, the team also combines knowledge distillation with local error signals to further boost performance. This breakthrough brings EP closer to practical use in resource-constrained machine learning and advances the pursuit of more biologically plausible learning methods.
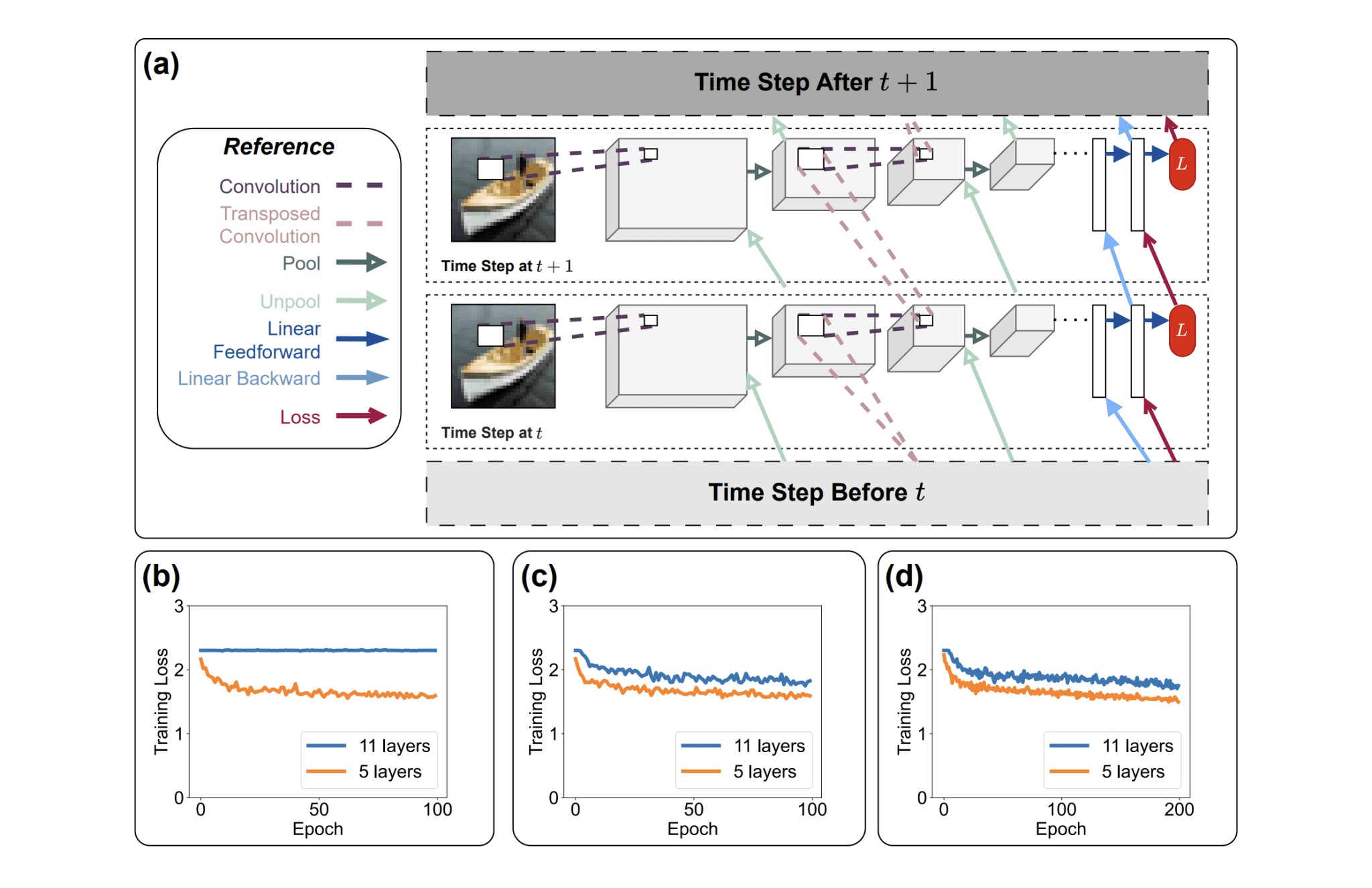
Figure 1. Equilibrium Propagation Solves Vanishing Gradients in Deep RNNs
Enhanced Equilibrium Propagation for Robust Learning
Researchers have developed an augmented Equilibrium Propagation (EP) framework to overcome instability in training deep neural networks. Unlike gradient descent, EP works by driving the network toward a stable state within its dynamics. The enhanced framework introduces intermediate learning signals that guide training, improve stability, and enable deeper architectures. By minimizing a mathematical function representing the network’s objective, EP uses loss functions at both output and intermediate layers to provide stronger learning signals.
Weights are updated based on local interactions, while a linear mapping technique aligns activations between a “teacher” and a “student” network to further stabilize learning. This approach delivers a new training method, theoretical insights into its convergence, and a path toward more stable, efficient training of deep neural networks—opening opportunities for deployment in more complex systems.
Equilibrium Propagation for Deep Network Training
Researchers have developed a new method for training deep neural networks using Equilibrium Propagation (EP), a biologically inspired learning rule that addresses the challenges of deeper architectures. By improving information flow and neuron dynamics, the approach tackles the vanishing gradient problem while enhancing stability. The framework trains convergent recurrent neural networks (CRNNs), where local error signals and knowledge distillation guide learning—enabling error signals to propagate backward, adjust synaptic weights, and refine gradient estimation.
The method mirrors biological processes, using convolution and pooling operations in forward passes and transposed convolutions with unpooling in backward passes to balance information flow. Intermediate error signals further strengthen gradient computations, making it possible to train much deeper CRNNs. Knowledge distillation, where a smaller “student” network learns from a larger “teacher” network, provides additional stability and performance gains. Demonstrated on CIFAR-10 and CIFAR-100, the approach significantly improves training outcomes, proving the scalability of EP and its potential for real-world AI applications.
Training Deeper Recurrent Networks with Equilibrium Propagation
Researchers have introduced a new framework for Equilibrium Propagation (EP), a biologically inspired learning rule, that greatly improves its scalability for deep neural networks. Traditional EP has struggled with vanishing gradients in deeper architectures, limiting convergence and performance. This enhanced approach integrates local error signals and knowledge distillation, strengthening information flow and stabilizing neuron dynamics to enable the training of much deeper convergent recurrent neural networks (CRNNs).
Testing on the CIFAR-10 and CIFAR-100 datasets shows the framework achieves state-of-the-art results, particularly with deep VGG architectures. Notably, VGG-11 CRNNs—previously hindered by vanishing gradients—exhibited significant improvements in training loss when trained with the augmented EP method. These findings demonstrate that combining local error signals with knowledge distillation overcomes prior EP limitations, presenting a biologically plausible alternative to backpropagation and opening new possibilities for neuromorphic computing and AI.
Scaling Deeper Networks with Lower Computational Cost
Researchers have introduced an enhanced framework for Equilibrium Propagation (EP), a biologically inspired learning rule, that overcomes the vanishing gradient problem in deep networks. By integrating intermediate error signals, the approach improves information flow and enables effective training of deeper architectures. Experiments on CIFAR-10 and CIFAR-100 using VGG networks show that this augmented EP achieves state-of-the-art accuracy while maintaining scalability, with no degradation in performance as network depth increases.
Compared to Backpropagation Through Time (BPTT), the framework substantially lowers GPU memory usage and computational overhead. Its reliance on local weight updates makes it well-suited for on-chip learning, with update mechanisms inspired by synaptic plasticity [1]. While the study centers on convolutional networks, the researchers suggest future work could extend the method to larger architectures such as advanced vision models and transformer-based language models. Although the use of additional weight matrices for knowledge distillation moderately increases memory requirements, this is considered an acceptable trade-off for the significant performance and efficiency gains.
References:
- https://quantumzeitgeist.com/researchers-overcome-vanishing-gradients-in-deep-recurrent-neural-networks-using-equilibrium-propagation/
Cite this article:
Janani R (2025), Researchers Tackle Vanishing Gradients in Deep RNNs with Equilibrium Propagation, AnaTechMaz, pp. 226
Recent Post
-
Researchers Tackle Vanishing Gradients in Deep RNNs with Equilibrium Propagation
Equilibrium Propagation (EP) is emerging as a....
-
Researchers Create Scalable Repeaters for Long-Distance Internet Communication
Quantum repeaters are essential for enabling secure....
-

Scientists Warn: New WIFI Technology Can Identify People Without Their Devices
Researchers at the Karlsruhe Institute of Technology (KIT) have...
-

Surfshark Unveils Ultra-Fast 100 Gbps VPN Servers, Setting New Speed Benchmark
Surfshark has announced the deployment of 100 Gbps servers.....
-

Advanced Online Protection: Essential Tools for Modern Internet Security
In an era where cyber threats are smarter, stealthier, and...
-

Mississippi’s Age Verification Law Challenges Decentralized Social Networks
A sweeping new age assurance law in Mississippi has sparked debate over....
-

Cisco: AI Drives Need for More Dependable Optical Networking Components
Cisco warns that as AI-driven networks increasingly rely...
-

Digital Twin Technology for Networks Encounters Challenges
By leveraging digital twin technology, network teams can model complex networks in software...
-

California Reduces the Impact of Ads on Streaming Platforms
California lawmakers are dialing down the volume on streaming ads. On October 6, Gov. Gavin Newsom...
-

OceanGate’s ‘Titan’ Made 7 Dives with a Compromised Hull Before Imploding
The U.S. National Transportation Safety Board (NTSB) has concluded...
-

Scientists Propose Quantum Network to Uncover the Universe’s Missing Matter
The team explored various network architectures — including...
-

IBM Broadens its Professional Service Offerings for Cisco Firewall Solutions
IBM Technology Lifecycle Services (TLS) has added Cisco’s...
-

Arista Expands its Networking Portfolio with AI Solutions
The company is growing its R4 family of high-capacity devices with several new additions: the 7020...
-

Enhancing Protection Through an Integrated Security and Networking Platform
As networks evolve, the traditional perimeter has vanished. Every...
-

Google and the U.S. government clash over the future of online advertising
Google is preparing to face the U.S. government in federal...