
Empowering AGI: Microsoft's KOSMOS-1 MLLM Breaks Boundaries with Perceptual Mastery, Instructional Finesse, and Contextual Learning Prowess
Large language models (LLMs) have proven to be highly effective in various natural language processing (NLP) tasks. However, the pursuit of artificial general intelligence (AGI), which aims to mimic human-like intelligence, requires enhancing these models with additional capabilities. One crucial advancement is enabling multimodal perception, which involves processing and understanding information from multiple modalities such as text, images, and audio. Incorporating multimodal perception into LLMs is a significant step towards bridging the gap between AI and human-level intelligence, as it allows for a more comprehensive understanding of the world.
In their recent paper titled "Language Is Not All You Need: Aligning Perception with Language Models," a team of researchers from Microsoft introduces KOSMOS-1, a ground breaking multimodal large language model (MLLM). KOSMOS-1 possesses the remarkable ability to perceive information across various modalities, engage in contextual learning, and comprehend and execute instructions. The model showcases exceptional performance in tasks related to language processing, perception-language alignment, and vision. By effectively integrating multimodal perception into language models, KOSMOS-1 represents a significant advancement in bridging the gap between language understanding and perceptual intelligence.

Figure 1. Beyond Limits: Microsoft's KOSMOS-1 MLLM Redefines AGI with Unparalleled Perceptual Skills and Adaptive Intelligence
Figure 1 shows the researchers argue that LLMs with multimodal perception will be better suited to gain common sense knowledge beyond what they can learn from text alone, and that this perception enrichment will allow LLMs to be used in new areas such as robotics and document intelligence. Multimodal perception also provides the advantage of bringing together many APIs into a single general graphical user interface.[1]
The development of KOSMOS-1 is based on the MetaLM training process, which involves enhancing a transformer-based large language model (LLM) with additional perception modules. Following the MetaLM philosophy, the research team considers language models as a universal task layer. In the case of KOSMOS-1, this approach allows the model to seamlessly integrate different task predictions in the form of text and effectively process natural-language instructions and action sequences. By unifying diverse tasks through the language model, KOSMOS-1 demonstrates the capability to handle a wide range of tasks while maintaining a consistent and versatile natural-language interface.
KOSMOS-1 utilizes an autoregressive approach to generate text based on a given context. It incorporates non-text input modalities by embedding them and feeding them into its backbone transformer-based causal language model. The transformer decoder acts as a versatile interface for all modalities, enabling KOSMOS-1 to interact with natural language as well as other modalities. This integration allows the model to naturally acquire the abilities of in-context learning and instruction following. Consequently, KOSMOS-1 is proficient in handling tasks that require both language processing and perception-intensive capabilities, making it a powerful tool for a wide range of tasks that involve language and perception.
During their empirical study, the research team trained KOSMOS-1 on large-scale multimodal datasets from the web. They extensively evaluated the model's performance on various language and multimodal tasks, as well as the Raven IQ test. The results were highly impressive, showcasing KOSMOS-1's exceptional performance across all tasks. The model demonstrated robust multimodal perception capabilities and showcased strong nonverbal reasoning abilities. This highlights the model's remarkable capacity to understand and process information from multiple modalities effectively, making it a highly capable and versatile system for a wide range of tasks.
The introduction of KOSMOS-1 represents a significant milestone in the field of multimodal large language models (MLLMs), offering promising new capabilities and opportunities. The researchers have ambitious plans for further development, including equipping KOSMOS-1 with speech-related capabilities. This expansion would enable the model to process and generate speech, further enhancing its multimodal capabilities. Additionally, there are plans to scale up the model size, potentially leading to even more impressive performance and a broader range of applications. These future advancements signify the researchers' commitment to pushing the boundaries of MLLMs and their continuous efforts to advance the field of artificial general intelligence.
In conclusion, Microsoft's KOSMOS-1 MLLM represents a significant breakthrough in the development of artificial general intelligence (AGI). With its remarkable perceptual mastery, instructional finesse, and contextual learning prowess, KOSMOS-1 surpasses previous boundaries in the field. The model's ability to perceive general modalities, follow instructions, and learn in context opens up new possibilities for AGI research and development. KOSMOS-1's impressive performance on language, perception-language, and vision tasks demonstrates its remarkable capabilities. As we move into 2023 and beyond, Microsoft's KOSMOS-1 MLLM holds great promise in shaping the future of AGI and pushing the boundaries of what is possible in the realm of intelligent systems.
References:
- https://syncedreview.com/2023/03/07/toward-agi-microsofts-kosmos-1-mllm-can-perceive-general-modalities-follow-instructions-and-perform-in-context-learning/ - comments
Cite this article:
Janani R (2023),Empowering AGI: Microsoft's KOSMOS-1 MLLM Breaks Boundaries with Perceptual Mastery, Instructional Finesse, and Contextual Learning Prowess , AnaTechMaz ,pp.87
Recent Post
-

Dimension reduction methods and techniques
Data smoothing is done by using an algorithm to remove noise from a data set. This allows important ......
-
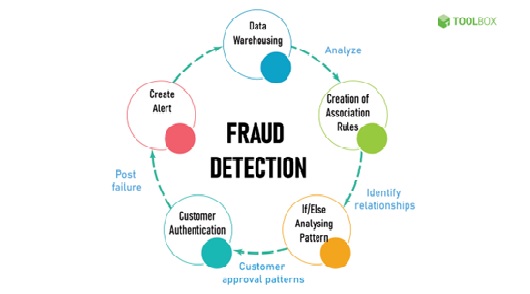
Fraud detection
Data mining to classify, cluster, and segment the data and automatically find associations and rules in the data that may signify interesting...
-
GIS and spatial data
Spatial data can be referred to as geographic data or geospatial data. Spatial data provides the information that identifies the location of ....
-

AI And Blockchain Are Being Combined for The Future of Data Analytics
The combination of artificial intelligence (AI) and blockchain technology ......
-

In The Absence Of 2FA, You Must Be Your Own Data Security Expert
Inspired by the rise of social media subscription structures, particularly 'Twitter Blue,' and how they .....
-

Automation Of Data Entry in Healthcare
The automation of data entry in healthcare is an increasingly important topic in 2023, as the healthcare ...
-

Contact Tracing Difficulties in A Post-COVID World
As we move into 2023 and continue to navigate a post-COVID world, there are still several challenges and ...
-

Data as a Service- Data Exchange in Marketplaces
You must have seen websites embedding Covid-19 data to show the number of cases in a region ...
-

2023 App Development Trends
2023 app development trends refer to the emerging and prominent shifts, technologies, and practices within the field of app development ...
-

The Power of Wireless Sensors: From Data to Insights
Wireless sensors are small devices used to detect environmental factors such as temperature,....
-

The Success of An LLM Is Dependent on High-Quality, Transparent Data
The Pursuing Full-Stack IT Observability summit is an event ........
-

Statistical Foundation for Data Science
Statistical Foundations of Data Science gives a thorough introduction to commonly used statistical ........
-

Metadata for Information Management
Often referred to as data that describes other data, metadata is structured reference data that helps to .......
-

Electric Field Modulation - The Future of Data Transmission
In today's interconnected world, our reliance on wireless technology has skyrocketed, prompting an ........