
Data Scraping in Cloud Computing
Data scraping is defined as a technique in which a computer program extracts a set of data with the help of output [1] generated from another program. The technique is commonly figure 1 shown below manifested in web scraping.

Figure 1. Data Scraping
Typically, companies do not want their unique content to be downloaded and reused for unauthorized purposes. As a result, they don’t expose all data via a consumable API or other easily accessible resource. Scraper bots, on the other hand, are interested in getting website data regardless of any attempt at limiting access. As a result, a cat-and-mouse game exists between web scraping bots and various content protection strategies, with each trying to outmaneuver the other.
The process of web scraping is fairly simple, though the implementation can be complex. Web scraping occurs in 3 steps:
- First the piece of code used to pull the information, which we call a scraper bot, sends an HTTP GET request to a specific website.
- When the website responds, the scraper parses the HTML document for a specific pattern of data.
- Once the data is extracted, it is converted into whatever specific format the scraper bot’s author designed.
Data scraping, in its most general form, refers to a technique in which a computer program extracts data from [2] output generated from another program. Data scraping is commonly manifest in web scraping, the process of using an application to extract valuable information from a website.
Several efforts can be made to minimize the attempt of bots to be limited. The visitor will be able to see the attempts by the bot. The following ways to minimize the data scraping are following:
Decrease the limit - This way allows users to prevent scraping so that a user or a scraper gets limited chances to perform some operation on the website. For example, we can limit searches per second from a particular IP address. This will make scraping ineffective. Also we can use a ReCaptcha entry if any task is completed faster than a real-world user speed.
Detect any theft activity - There can be many theft activities such as searching for a number of pages on the website, many similar requests from the same IP address, an unusual number of searches, etc. This can be prevented by asking the captcha for subsequent requests.
Miscellaneous indicators - Some other indicators use how fast a user fills a form. We can use javascript to identify the users, their HTTP headers, orders, etc. For example, if we get the same request from the user often, the button clicked on the form is in the same place, screen sizes are the same, probably it is a scraper bot.
Data scraping is a way of extracting data generated by another program. Its most common use is web scraping, whereby the scraper grabs information from a website.
It is a way of getting around the fact that some companies try to avoid having their content downloaded or reused for unauthorized purposes. Perhaps they want users to register, become a subscriber or pay before they can gain full access to knowledge. Whatever the reason, these companies use access and permission controls and other means to prevent the exposure of the data via an easily consumable API. Data scraping can circumvent such safeguards.
References:
- https://www.javatpoint.com/what-is-data-scraping
- https://www.cloudflare.com/learning/bots/what-is-data-scraping/
- https://www.datamation.com/big-data/data-scraping/
Cite this article:
Nandhinidwaraka. S (2021), Data Scraping in Cloud Computing, AnaTechMaz, pp. 41
Recent Post
-

Industry Cloud in 2021
SAP’s industry cloud simplifies access to innovative vertical solutions across industries. Built by SAP and our partners on an open platform...
-

Cloud Operating System Virtualization
In operating system virtualization in Cloud Computing, the virtual machine software...
-

Containerization in Cloud Computing
A container is a portable computing environment. It contains everything an application needs to run...
-

Open Source Cloud Computing
Open source is a term that originally referred to open source software (OSS). Open source software is code that is designed...
-

The Pros and Cons of Cloud Agnostic
Being Cloud Agnostic means building your architecture to utilize everything open source technologies...
-
The Cloud-Storage Virtualization
In the computing or Cloud computing domain, virtualization refers to the creation of virtual resources (like a virtual server, virtual storage...
-
Difference Between Grid Computing Vs Cloud Computing
Grid computing is also called as distributed computing. It links multiple computing resources...
-
The Cloud Network Services System
Network-as-a-service (NaaS) is a cloud service model in which customers rent networking services...
-
Technology of Cloud Cube Model
Green cloud is a buzzword that refers to the potential environmental benefits that information technology (IT) services delivered over the Internet...
-
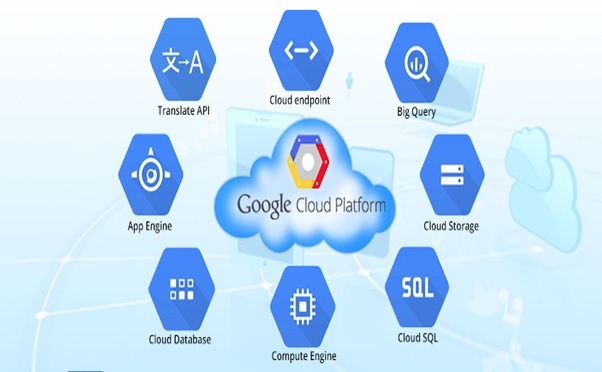
Development of Google Cloud Platform
Google Cloud Platform is a set of Computing, Networking, Storage, Big Data, Machine Learning...
-
Data Scraping in Cloud Computing
Data scraping is defined as a technique in which a computer program extracts a set of data with the help of output generated from another program...
-
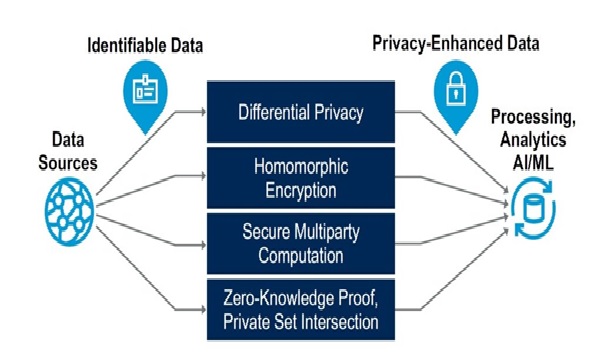
Privacy-Enhancing Computation (PEC)
The amount of data generated and processed every day is enormous. Thanks to modern technologies...
-
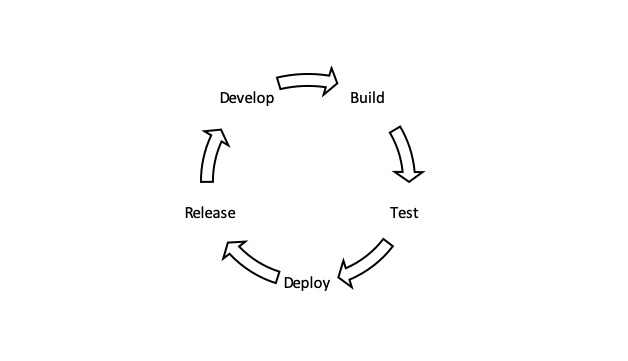
The Cloud-Native Platform
The term “cloud native” refers to an approach to building and running applications that takes full advantage of a cloud computing delivery...
-
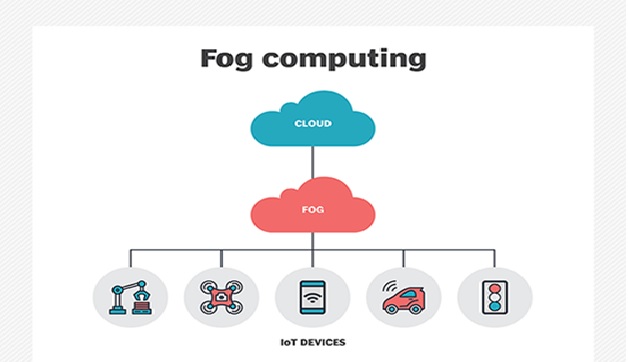
Technologies of Fog Computing
Fog Computing is the term coined by Cisco that refers to extending cloud computing to an edge of the enterprise’s network...
-

Sandboxing in Cloud Computing
In the world of cybersecurity, a sandbox environment is an isolated virtual machine in which potentially unsafe software code can execute...