
A Unified Theory on How Neural Networks Represent Data in Deep Learning
How do neural networks work? It’s a question that puzzles both beginners and experts. Researchers at MIT’s CSAIL argue that understanding how neural networks represent and learn from data is essential for enhancing their interpretability, efficiency, and generalizability.
With this in mind, CSAIL researchers have introduced a new framework to explain how neural networks form representations. Their Canonical Representation Hypothesis (CRH) suggests that during training, neural networks naturally align their latent representations, weights, and neuron gradients within each layer. This alignment indicates that neural networks inherently develop compact representations based on how they deviate from the CRH.

Figure 1. Neural Networks & Data: A Unifying Theory
Senior author Tomaso Poggio explains that understanding and utilizing this alignment could help engineers design more efficient and interpretable networks. The research, available on the arXiv preprint server, also introduces the Polynomial Alignment Hypothesis (PAH) [1]. This hypothesis suggests that when the Canonical Representation Hypothesis (CRH) is disrupted, distinct phases emerge where representations, gradients, and weights become polynomially related. Poggio notes that CRH and PAH provide a potential unifying theory for deep learning phenomena like neural collapse and the neural feature ansatz (NFA). Figure 1 shows Neural Networks & Data: A Unifying Theory.
The new CSAIL paper presents experimental results across different settings, supporting the CRH and PAH in tasks like image classification and self-supervised learning. The CRH also suggests the potential for manually injecting noise into neuron gradients to shape model representations. Poggio highlights a key future direction: understanding the conditions that trigger each phase and how these phases influence model behavior and performance.
"The paper offers a fresh perspective on understanding how representations form in neural networks through the CRH and PAH," says Poggio. "It provides a framework for unifying existing observations and guiding future research in deep learning."
Co-author Liu Ziyin, a postdoc at CSAIL, adds that the CRH could explain certain phenomena in neuroscience, as it suggests neural networks learn orthogonalized representations, a concept observed in recent brain studies. This could also have algorithmic implications: if representations align with gradients, it might be possible to inject noise into neuron gradients to design specific structures within the model’s representations.
Ziyin and Poggio co-authored the paper with Professor Isaac Chuang and former postdoc Tomer Galanti, now an assistant professor of computer science at Texas A&M University [2]. They are set to present their findings later this month at the International Conference on Learning Representations (ICLR 2025) in Singapore.
Reference:
- https://www.csail.mit.edu/news/how-neural-networks-represent-data
- https://techxplore.com/news/2025-04-neural-networks-potential-theory-key.html
Cite this article:
Janani R (2025), A Unified Theory on How Neural Networks Represent Data in Deep Learning, AnaTechMaz, pp. 591
Recent Post
-

Technologies of Connected Car
A connected car is one that has its own connection to the internet, usually via a wireless local area network (WLAN)...
-
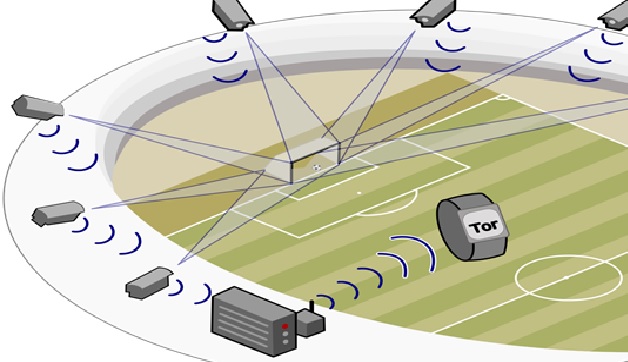
Technologies of Goal-line
Goal-line technology in football is a technology system used to determine whether a ball has crossed the goal line or not...
-
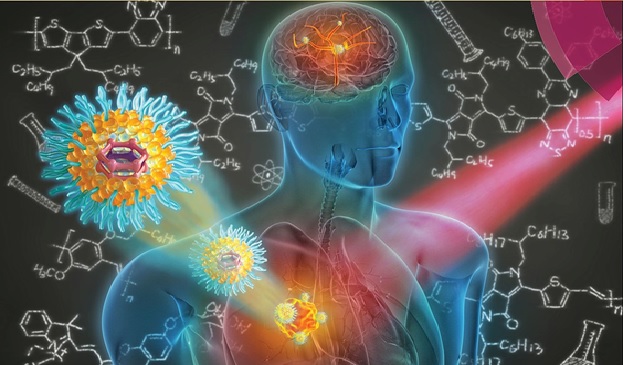
The Application of Nanotechnology in Nanomedicines
Nanomedicine is defined as the medical application of nanotechnology. Nanomedicine can include a wide...
-
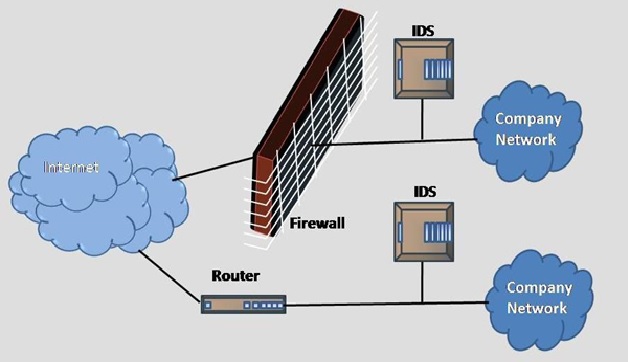
The Methods of Intrusion Detection System
Intrusion detection systems are designed to identify suspicious and malicious activity through network...
-

The Thermal and Infrared Imaging Technology
Thermal imaging is a method of using infrared radiation and thermal energy to gather information about objects...
-

Thermography in engineering
Thermography involves the use of thermal imagers, which are sophisticated devices that measure the natural emission...
-
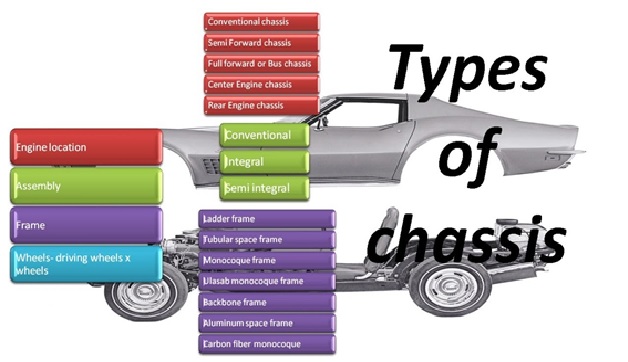
Types of Chassis Frames
Chassis frame is the basic frame work of the automobile. It supports all the parts of the automobile attached to it...
-

Types of Stepper Motor
Stepper Motor is a brushless electromechanical device which converts the train of electric pulses applied...
-

Types of Tamper Resistance
Tamper resistance is the ability of a device to defend against a threat that has the objective to compromise the device...
-

Unified Modeling Language (UML)
UML, short for Unified Modeling Language, is a standardized modeling language consisting of an integrated set of diagrams...
-
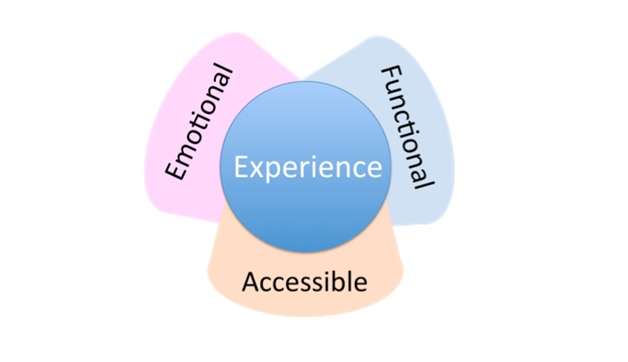
Values of Total Experience
Total experience (TX) is a strategy that creates superior shared experiences by interlinking the user experience...
-
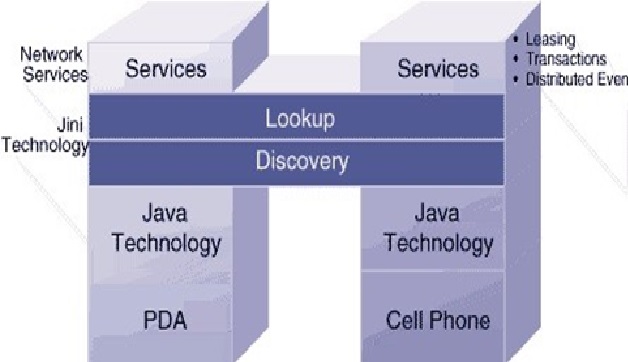
Works of Jini Technology
Jini is a service-oriented architecture that defines a programming model that both exploits and extends Java technology...
-

Overview of Swarm Robotics
Swarms typically consist of many individual, simple, and homogeneous or heterogeneous agents (Dorigo and Birattari...
-
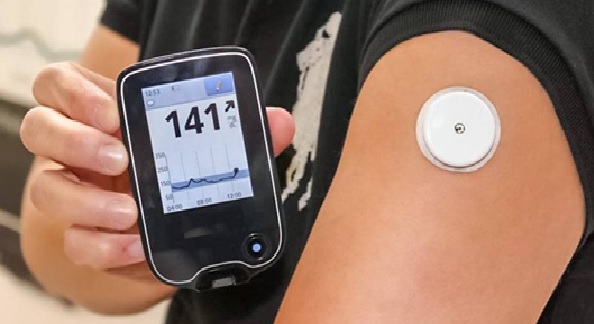
Continuous Glucose Monitoring (CGM Technology)
A CGM is a compact medical system that continuously monitors your glucose levels in more or less real time...
-
Digital Humans
Digital human technology takes artificial intelligence (AI) applications to a whole new level. It purports that you can have 3D...