
Researchers Train LLMs to Tackle Complex Planning Problems
This new framework utilizes a model's reasoning capabilities to create a "smart assistant" that determines the best solution for multistep challenges. For example, consider a coffee company aiming to optimize its supply chain. The company sources beans from three suppliers, roasts them at two facilities into either dark or light coffee, and then distributes the roasted coffee to three retail locations. Each supplier has a different capacity, and both roasting and shipping costs vary by location. The goal is to minimize costs while accommodating a 23% increase in demand.
While it might seem like simply asking ChatGPT to generate an optimal plan would be the easiest solution, large language models (LLMs) often struggle with directly solving complex planning problems on their own. Instead of trying to enhance the LLM’s planning abilities, MIT researchers took a different route. They developed a framework that helps guide the LLM to break down the problem in a human-like manner, and then automatically solve it using a powerful software tool.

Figure 1. Researchers Train LLMs for Complex Planning
Users simply describe their problem in natural language—no specialized training or examples are needed. The LLM translates the prompt into a structured format for an optimization solver, which efficiently tackles complex planning challenges. Figure 1 shows Researchers Train LLMs for Complex Planning.
During this process, the LLM verifies its work at multiple steps, correcting any errors rather than abandoning the task. When tested on nine complex planning problems, such as optimizing warehouse robot travel distances, the framework achieved an 85% success rate—far surpassing the 39% success rate of the best baseline.
The framework is adaptable to various complex planning tasks, from scheduling airline crews to optimizing factory machine time.
“Our research introduces a framework that acts as a smart assistant for planning problems. It determines the best plan that meets all requirements, even with complex or unusual rules,” says Yilun Hao, an MIT graduate student and lead author.
Optimization Basics
That’s when the framework really gets to work. It translates these problem components into a formal mathematical representation that a solver can process. Unlike previous approaches, which often rely on static templates, LLMFP dynamically adapts based on the problem’s complexity, ensuring a precise formulation.
One of its most impressive features is its self-correction mechanism. If the model detects inconsistencies or errors in the formulation, it doesn’t abandon the task—instead, it iteratively refines its approach. This built-in verification process significantly enhances the reliability of the final solution.
During rigorous testing across various real-world challenges—ranging from optimizing delivery routes to balancing workloads in cloud computing—LLMFP outperformed traditional baseline methods. Its ability to bridge the gap between human intuition and algorithmic precision makes it a valuable tool for industries seeking efficient decision-making solutions.
Ultimately, this research highlights how LLMs, when properly guided, can act as intermediaries between human planners and sophisticated solvers, making advanced optimization accessible to a broader audience.
Refining the Strategy
The self-assessment module enables the LLM to refine its problem formulation by identifying and correcting implicit constraints it initially overlooked. For example, while optimizing a coffeeshop’s supply chain, the model might not realize that shipping a negative amount of roasted beans is impossible. The self-assessment step detects such errors and prompts the model to adjust its formulation accordingly.
Additionally, the framework adapts to user preferences—if a user prefers not to alter their travel budget or schedule, the LLM suggests alternative modifications that align with their needs.
In evaluations across nine diverse planning problems, LLMFP achieved an 83–87% success rate, nearly doubling the performance of baseline methods. Unlike domain-specific approaches, it requires no specialized training examples and works immediately out of the box. Users can also customize LLMFP for different optimization solvers by adjusting prompts.
Future research aims to enhance LLMFP by incorporating image inputs to better tackle complex problems that are difficult to describe solely in natural language. This work was supported by the Office of Naval Research and the MIT-IBM Watson AI Lab.
Source: MIT News
Cite this article:
Janani R (2025), Researchers Train LLMs to Tackle Complex Planning Problems, AnaTechMaz, pp. 590
Recent Post
-

Technologies of Connected Car
A connected car is one that has its own connection to the internet, usually via a wireless local area network (WLAN)...
-
Technologies of Goal-line
Goal-line technology in football is a technology system used to determine whether a ball has crossed the goal line or not...
-
The Application of Nanotechnology in Nanomedicines
Nanomedicine is defined as the medical application of nanotechnology. Nanomedicine can include a wide...
-
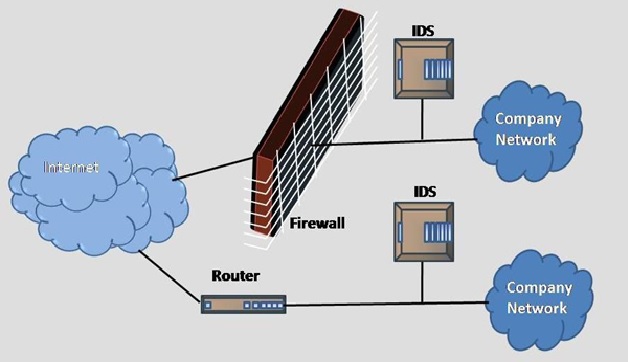
The Methods of Intrusion Detection System
Intrusion detection systems are designed to identify suspicious and malicious activity through network...
-

The Thermal and Infrared Imaging Technology
Thermal imaging is a method of using infrared radiation and thermal energy to gather information about objects...
-

Thermography in engineering
Thermography involves the use of thermal imagers, which are sophisticated devices that measure the natural emission...
-
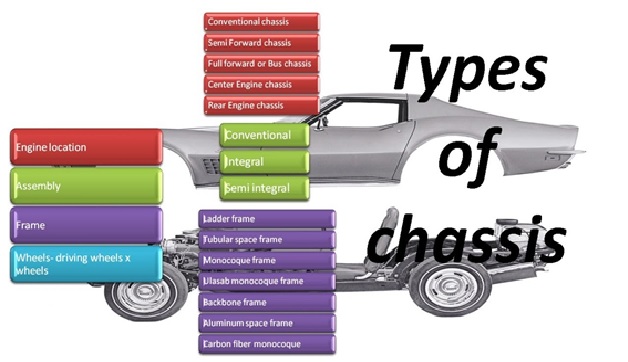
Types of Chassis Frames
Chassis frame is the basic frame work of the automobile. It supports all the parts of the automobile attached to it...
-

Types of Stepper Motor
Stepper Motor is a brushless electromechanical device which converts the train of electric pulses applied...
-

Types of Tamper Resistance
Tamper resistance is the ability of a device to defend against a threat that has the objective to compromise the device...
-

Unified Modeling Language (UML)
UML, short for Unified Modeling Language, is a standardized modeling language consisting of an integrated set of diagrams...
-
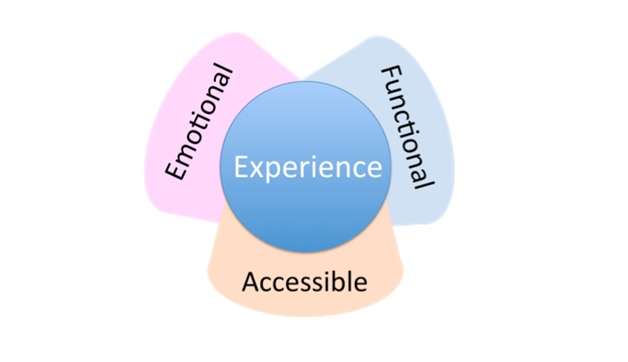
Values of Total Experience
Total experience (TX) is a strategy that creates superior shared experiences by interlinking the user experience...
-
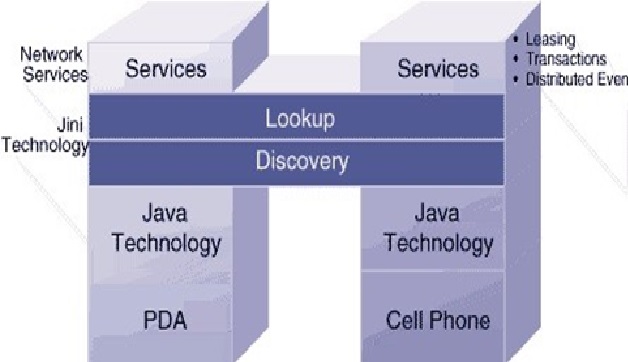
Works of Jini Technology
Jini is a service-oriented architecture that defines a programming model that both exploits and extends Java technology...
-

Overview of Swarm Robotics
Swarms typically consist of many individual, simple, and homogeneous or heterogeneous agents (Dorigo and Birattari...
-
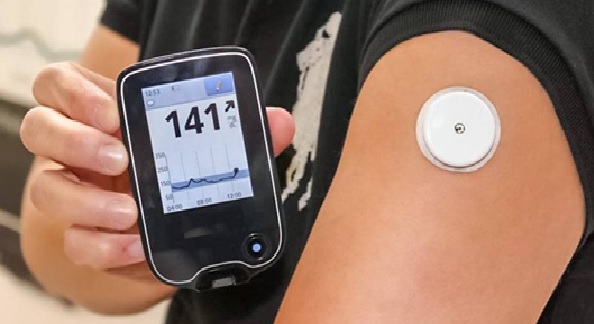
Continuous Glucose Monitoring (CGM Technology)
A CGM is a compact medical system that continuously monitors your glucose levels in more or less real time...
-
Digital Humans
Digital human technology takes artificial intelligence (AI) applications to a whole new level. It purports that you can have 3D...