
New GenAI Hybrid Tool Generates Realistic Images Quickly and Efficiently
This innovative method operates nine times faster and consumes fewer resources compared to current diffusion models. The ability to generate high-quality images rapidly is essential for creating realistic simulated environments, helping train self-driving cars to navigate unpredictable hazards and enhance street safety.
Generative AI techniques used to create realistic images come with trade-offs. Diffusion models, while capable of producing high-quality images, are slow and resource-heavy. In contrast, autoregressive models, like those used in LLMs such as ChatGPT, are faster but generate lower-quality images with more errors.

Figure 1. New Hybrid GenAI Tool Creates Realistic Images Quickly
Researchers from MIT and NVIDIA have developed HART (Hybrid Autoregressive Transformer), a new tool that combines the strengths of both autoregressive and diffusion models. HART uses an autoregressive model for quick broad image creation, followed by a smaller diffusion model to refine details [1]. This approach allows HART to generate images of comparable or superior quality to advanced diffusion models, but about nine times faster. Figure 1 shows New Hybrid GenAI Tool Creates Realistic Images Quickly.
HART's generation process requires fewer computational resources than traditional diffusion models, allowing it to run locally on devices like commercial laptops or smartphones. Users can simply input a natural language prompt to generate an image. This makes HART highly versatile, with potential applications in areas such as training robots for complex tasks and assisting designers in creating stunning scenes for video games.
Haotian Tang PhD '25, co-lead author of a paper on HART, explains the concept by comparing it to painting: starting with the big picture and then refining the details with smaller brushstrokes results in a better final image. Tang is joined by co-lead author Yecheng Wu, an undergraduate at Tsinghua University, and senior author Song Han, an associate professor at MIT and distinguished scientist at NVIDIA. The research will be presented at the International Conference on Learning Representations.
Combining the Best of Both Worlds
Popular diffusion models like Stable Diffusion and DALL-E are known for producing detailed images, but they are slow and resource-intensive due to their iterative process of predicting and removing noise from each pixel across multiple steps. In contrast, autoregressive models are faster but less accurate, as they predict images sequentially without the ability to correct mistakes, resulting in lower-quality images.
To combine the strengths of both, the HART model uses an autoregressive model to predict compressed image tokens quickly, followed by a small diffusion model to refine and correct the details lost during compression. This hybrid approach significantly improves image quality, especially for intricate details like edges and facial features, while maintaining speed. By reducing the number of diffusion steps required, HART achieves high-quality results in just eight steps, enhancing efficiency and preserving the speed advantage of autoregressive models.
Surpassing Larger Models
While developing HART, the researchers faced challenges in integrating the diffusion model effectively with the autoregressive model. They found that applying the diffusion model early in the process led to an accumulation of errors. Their final design, however, where the diffusion model predicts only residual tokens as the final step, significantly improved image generation quality.
The HART model, which combines a 700-million-parameter autoregressive transformer and a lightweight 37-million-parameter diffusion model, generates images of similar quality to those created by a 2-billion-parameter diffusion model, but nine times faster and with 31% less computational cost.
Additionally, since HART utilizes an autoregressive model, it is more compatible with unified vision-language generative models, making it an ideal candidate for integration into new multimodal AI systems [2]. The researchers also aim to build vision-language models on top of HART and extend its use to video generation and audio prediction tasks.
This research was supported by the MIT-IBM Watson AI Lab, the MIT and Amazon Science Hub, the MIT AI Hardware Program, and the National Science Foundation, with GPU infrastructure donated by NVIDIA.
Reference:
- https://news.mit.edu/2025/ai-tool-generates-high-quality-images-faster-0321
- https://www.labmanager.com/new-hybrid-genai-tool-quickly-and-efficiently-creates-realistic-images-33780
Cite this article:
Janani R (2025), New GenAI Hybrid Tool Generates Realistic Images Quickly and Efficiently, AnaTechMaz, pp. 587
Recent Post
-

Technologies of Connected Car
A connected car is one that has its own connection to the internet, usually via a wireless local area network (WLAN)...
-
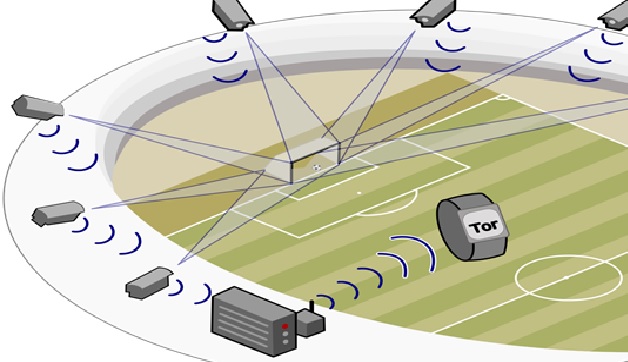
Technologies of Goal-line
Goal-line technology in football is a technology system used to determine whether a ball has crossed the goal line or not...
-
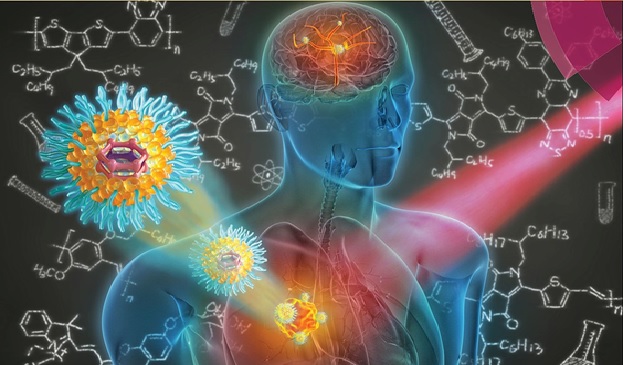
The Application of Nanotechnology in Nanomedicines
Nanomedicine is defined as the medical application of nanotechnology. Nanomedicine can include a wide...
-
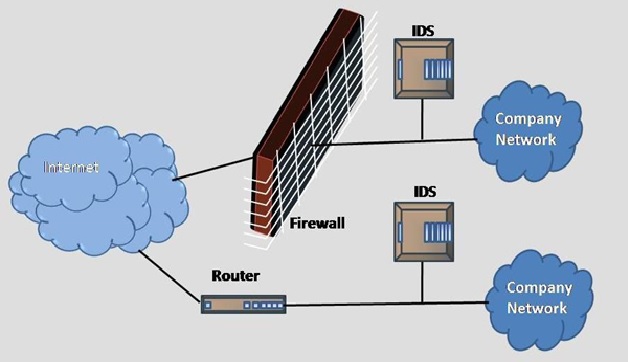
The Methods of Intrusion Detection System
Intrusion detection systems are designed to identify suspicious and malicious activity through network...
-

The Thermal and Infrared Imaging Technology
Thermal imaging is a method of using infrared radiation and thermal energy to gather information about objects...
-

Thermography in engineering
Thermography involves the use of thermal imagers, which are sophisticated devices that measure the natural emission...
-
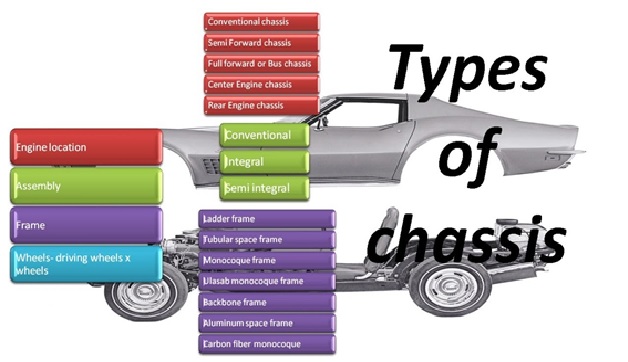
Types of Chassis Frames
Chassis frame is the basic frame work of the automobile. It supports all the parts of the automobile attached to it...
-

Types of Stepper Motor
Stepper Motor is a brushless electromechanical device which converts the train of electric pulses applied...
-

Types of Tamper Resistance
Tamper resistance is the ability of a device to defend against a threat that has the objective to compromise the device...
-

Unified Modeling Language (UML)
UML, short for Unified Modeling Language, is a standardized modeling language consisting of an integrated set of diagrams...
-
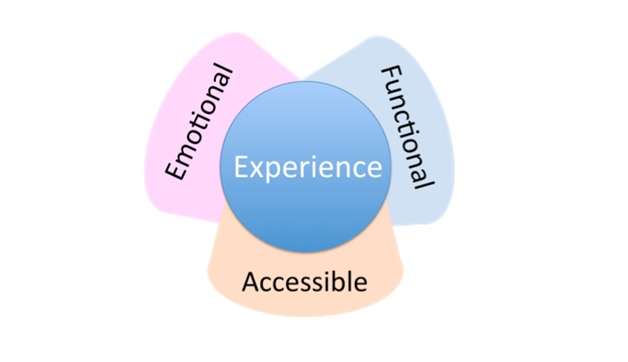
Values of Total Experience
Total experience (TX) is a strategy that creates superior shared experiences by interlinking the user experience...
-
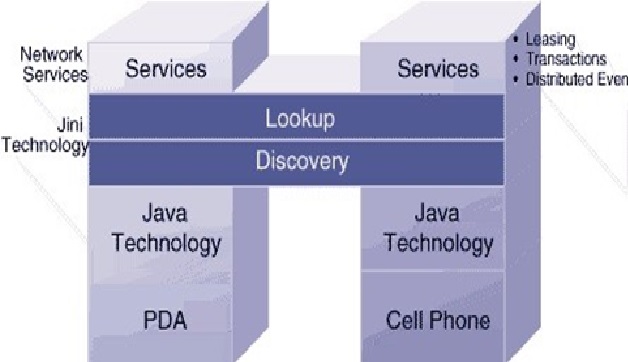
Works of Jini Technology
Jini is a service-oriented architecture that defines a programming model that both exploits and extends Java technology...
-

Overview of Swarm Robotics
Swarms typically consist of many individual, simple, and homogeneous or heterogeneous agents (Dorigo and Birattari...
-
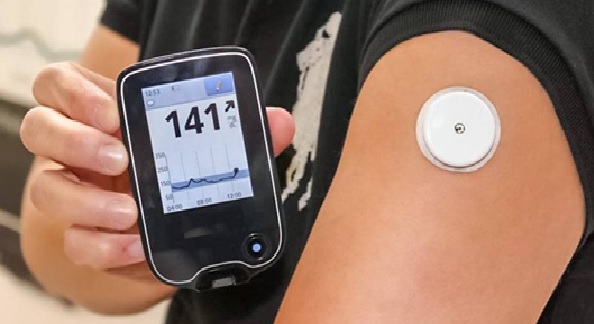
Continuous Glucose Monitoring (CGM Technology)
A CGM is a compact medical system that continuously monitors your glucose levels in more or less real time...
-
Digital Humans
Digital human technology takes artificial intelligence (AI) applications to a whole new level. It purports that you can have 3D...