
PlatoNeRF: Enhancing Autonomous Vehicles and AR/VR with Advanced 3D Scene Reconstruction Technology
Imagine driving through a tunnel in an autonomous vehicle, unaware that a crash has halted traffic ahead. Typically, you’d rely on the car in front to know when to brake. But what if your vehicle could anticipate the need to stop by "seeing" around the car in front of you?
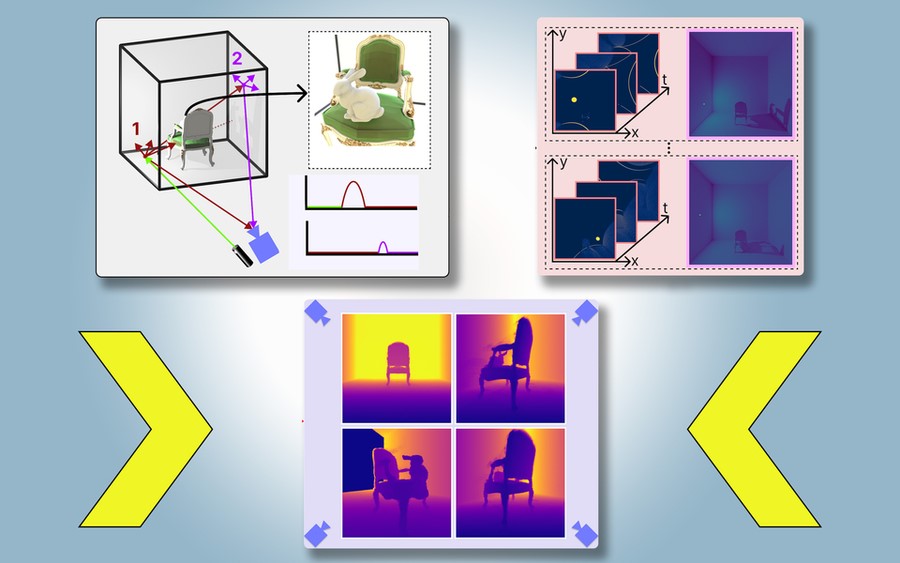
Figure 1. PlatoNeRF. (Credit: MIT)
Researchers from MIT and Meta have developed a computer vision technique that could make this possible. They introduced a method called PlatoNeRF, which creates accurate 3D models of a scene, including hidden areas, using images from a single camera position. This technique leverages shadows to detect what lies in obstructed portions of the scene.
Inspired by Plato’s allegory of the cave, where prisoners infer the reality of the outside world from shadows, PlatoNeRF combines lidar (light detection and ranging) technology with machine learning to generate precise 3D reconstructions. It performs better than some existing AI techniques, especially in conditions with high ambient light or dark backgrounds, where shadows are hard to discern.
Beyond enhancing autonomous vehicle safety, PlatoNeRF could also improve AR/VR headsets by enabling users to model room geometry without extensive measurements and help warehouse robots locate items in cluttered environments more efficiently.
“Our key idea was combining two previously separate disciplines — multibounce lidar and machine learning. This synergy opens up new opportunities and yields the best of both worlds,” explains Tzofi Klinghoffer, an MIT graduate student in media arts and sciences and lead author of a paper on PlatoNeRF.
Klinghoffer collaborated on the paper with his advisor, Ramesh Raskar, associate professor of media arts and sciences and leader of the Camera Culture Group at MIT; Rakesh Ranjan, senior author and director of AI research at Meta Reality Labs; and other researchers from MIT and Meta. The research will be presented at the Conference on Computer Vision and Pattern Recognition.
Illuminating the Challenge
Creating a full 3D scene from a single camera viewpoint is a complex task. Some machine-learning approaches use generative AI models to guess what’s hidden, but these models can sometimes imagine objects that aren’t there. Other methods infer hidden shapes from shadows in color images, but they struggle when shadows are hard to see.
The MIT researchers built PlatoNeRF using single-photon lidar, which provides higher-resolution data by detecting individual photons. This lidar illuminates a target point, with most light scattering off other objects before returning to the sensor. PlatoNeRF uses these secondary light bounces to capture additional scene information, including depth and shadows.
By calculating the time it takes for light to bounce twice and return, PlatoNeRF traces these secondary rays to identify shadowed points, inferring the geometry of hidden objects. The lidar sequentially illuminates 16 points to reconstruct the entire 3D scene.
“Each time we illuminate a point, we create new shadows. With multiple illumination sources, we carve out occluded regions beyond visible areas,” Klinghoffer explains.
A Powerful Combination
PlatoNeRF’s success lies in combining multibounce lidar with a neural radiance field (NeRF), a machine-learning model that encodes scene geometry into a neural network’s weights. This combination results in highly accurate scene reconstructions.
“The biggest challenge was integrating these two elements. We had to consider the physics of light transport with multibounce lidar and model it with machine learning,” Klinghoffer says.
PlatoNeRF outperformed methods that solely used lidar or NeRF with a color image, especially with lower-resolution lidar sensors, making it more practical for real-world deployment.
“About 15 years ago, our group invented the first camera to ‘see’ around corners using multiple light bounces. Since then, lidar technology has advanced, enabling our research on cameras that can see through fog. This new work uses only two light bounces, resulting in high signal-to-noise ratio and impressive 3D reconstruction quality,” Raskar says.
Future research will explore tracking more than two light bounces to enhance scene reconstructions further. Additionally, the team plans to incorporate deep learning techniques and combine PlatoNeRF with color image measurements to capture texture information.
Source: Massachusetts Institute of Technology
Cite this article:
Hana M (2024), PlatoNeRF: Enhancing Autonomous Vehicles and AR/VR with Advanced 3D Scene Reconstruction Technology, AnaTechMaz, pp. 405
Recent Post
-

Intel Has Unveiled the Largest Neuromorphic Computer Inspired by The Brain
Intel has developed the world's largest neuromorphic computer, aiming to replicate...
-

AI Using Satellite Images Has Detected Ships Engaged in Smuggling Russian Oil
Artificial intelligence has the capability to analyze satellite imagery, uncovering the...
-

Life-Saving Hospital Trial Utilizes AI Predicting Mortality Risk
In a groundbreaking clinical trial involving nearly 16,000 patients across two...
-

GPT-4: 82% More Persuasive Than Humans, And AI Now Reads Emotions
New research indicates that GPT-4 surpasses the average human in...
-
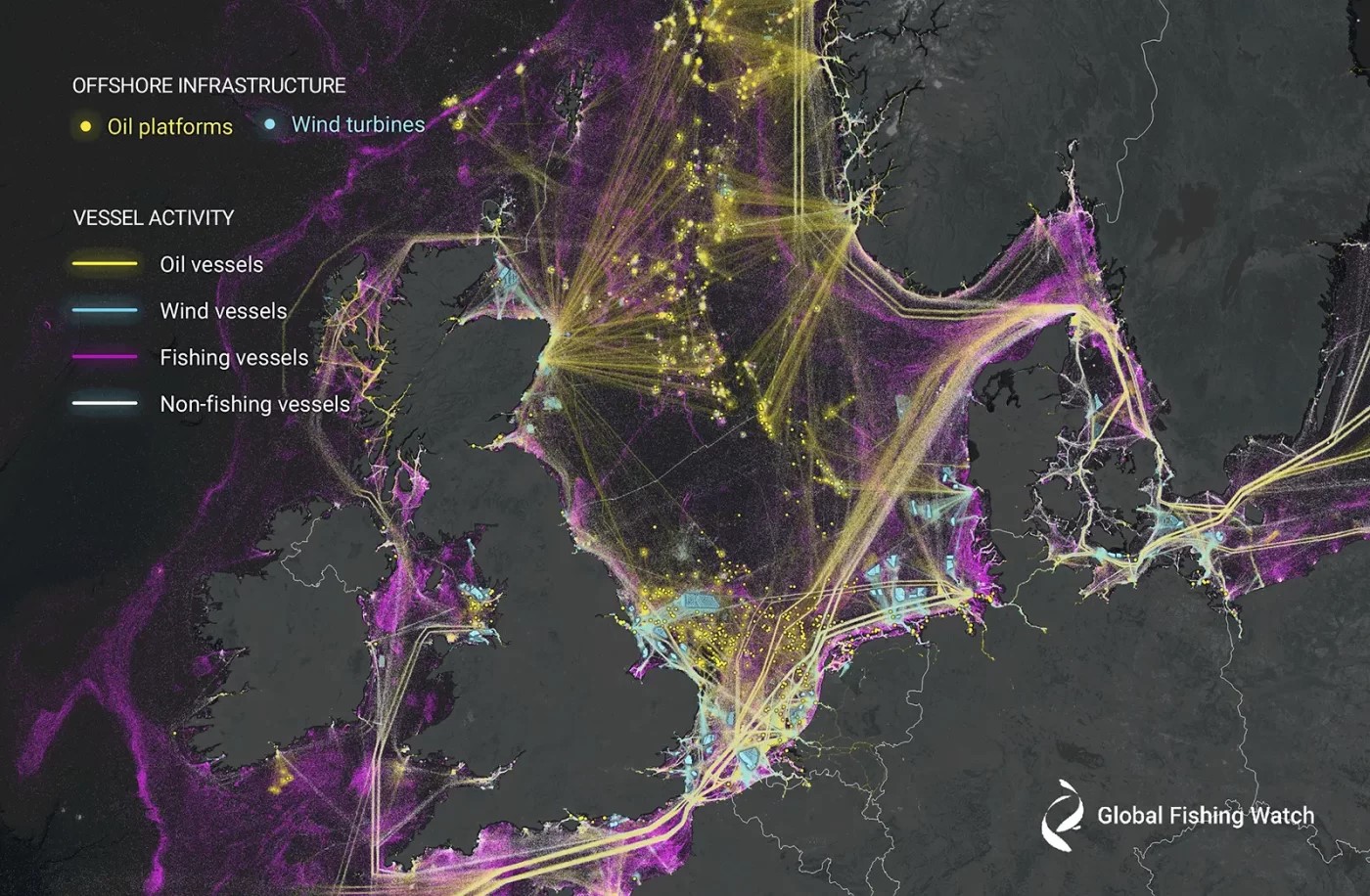
Utilizing AI and Satellite Imagery to Map Hidden Ocean Activities, Including Fishing, Shipping, and Energy Development
Humans are rushing to tap into the immense potential of the ocean to drive...
-

Advancements In Robotics: AI-Powered Robots Now Autonomously Repairing Other Bots
In January, researchers showcased the culinary abilities of an open-source...
-

Advancing Humanoids: Ubtech's Walker S Equipped with Conversational AI
Continuing the momentum set by the GPT-enhanced Figure 01 humanoid that...
-
AI Risk Assessment System Proves Life-Saving in Hospital Trial
"An AI system has shown its life-saving potential by notifying doctors of patients...
-

Hybrid Rescue Drone Transforms into Lifebuoy to Aid Swimmers
You might not be able to physically toss a lifebuoy to a swimmer one kilometer....
-

Here's Why Artificial Intelligence Such as ChatGPT Likely Won't Achieve Human-Like Understanding
If you were to inquire of ChatGPT whether it possesses human-like thought...
-

AI Bot Showdown: Copilot Vs ChatGPT Vs Gemini
In the age of artificial intelligence (AI), chatbots have become essential ...
-
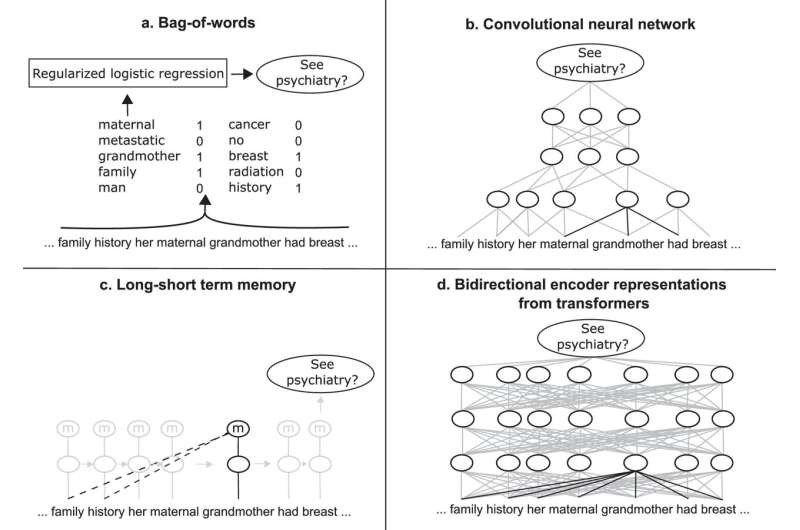
AI Model Predicts Need for Mental Health Services in Cancer Care
Researchers from UBC and BC Cancer have developed an innovative artificial...
-

AI Method Improves Identification of Toxic Chemicals and Reduces Reliance on Animal Testing
Researchers at Chalmers University of Technology and the University of ...
-

Introducing ChemCrow, the Revolutionary AI in Chemistry
In the realm of chemistry, automation has long been a formidable challenge...
-
PlatoNeRF: Enhancing Autonomous Vehicles and AR/VR with Advanced 3D Scene Reconstruction Technology
Imagine driving through a tunnel in an autonomous vehicle, unaware that a crash...