
Overview of Hadoop Architecture
Apache Hadoop is an open source software framework used to develop data processing applications which are executed in a distributed computing environment.
Applications built using HADOOP are run on large data sets distributed across clusters of commodity computers. Commodity computers are cheap and widely available. These are mainly useful for achieving greater computational power at low cost. [2]
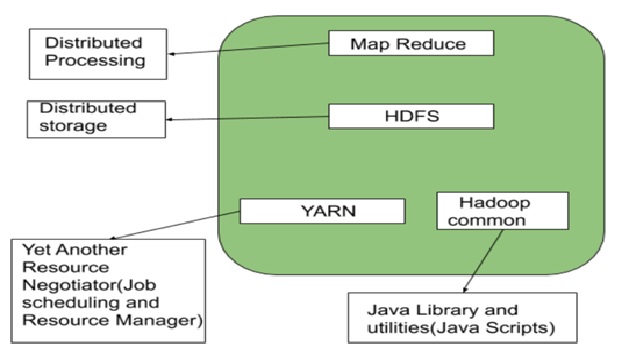
Figure 1. Overview of Hadoop Architecture
Figure 1 shows The Hadoop architecture is a package of the file system, MapReduce engine and the HDFS (Hadoop Distributed File System). The MapReduce engine can be MapReduce/MR1 or YARN/MR2.
A Hadoop cluster consists of a single master and multiple slave nodes. The master node includes Job Tracker, Task Tracker, NameNode, and DataNode whereas the slave node includes DataNode and TaskTracker. [3]
As we all know Hadoop is a framework written in Java that utilizes a large cluster of commodity hardware to maintain and store big size data. Hadoop works on MapReduce Programming Algorithm that was introduced by Google. Today lots of Big Brand Companys are using Hadoop in their Organization to deal with big data for eg. Facebook, Yahoo, Netflix, eBay, etc. [4]
Hadoop Architecture Overview
Apache Hadoop offers a scalable, flexible and reliable distributed computing big data framework for a cluster of systems with storage capacity and local computing power by leveraging commodity hardware. Hadoop follows a Master Slave architecture for the transformation and analysis of large datasets using Hadoop MapReduce paradigm.
The components that play a vital role in the Hadoop architecture are -
- Hadoop Common– It contains libraries and utilities that other Hadoop modules require;
- Hadoop Distributed File System (HDFS)– A distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster; patterned after the UNIX file system and provides POSIX-like semantics.
- Hadoop YARN – Introduced in 2012, this is a platform that is in charge of managing computing resources in clusters and utilising them for planning users' applications.
- Hadoop MapReduce – This is an application of the MapReduce programming model for large-scale data processing. Both Hadoop's MapReduce and HDFS, were inspired by Google's papers on MapReduce and Google File System.
- Hadoop Ozone – This is a scalable, redundant, and distributed object store for Hadoop. This is a new addition (introduced in 2020) to the Hadoop family and unlike HDFS, it can handle both small and large files alike. [1]
References:
- https://www.projectpro.io/article/hadoop-architecture-explained-what-it-is-and-why-it-matters/317
- https://www.guru99.com/learn-hadoop-in-10-minutes.html
- https://www.javatpoint.com/what-is-hadoop
- https://www.geeksforgeeks.org/hadoop-architecture/
Cite this article:
Nandhinidwaraka S (2021) Overview of Hadoop Architecture, AnaTechMaz, pp. 31
Recent Post
-
Overview of Hadoop Architecture
Apache Hadoop is an open source software framework used to develop data processing applications which are executed in a distributed ....
-
Overview of Java Database Connectivity
JDBC is an acronym for Java Database Connectivity. It’s an advancement for ODBC (Open Database ...
-

The Big Data-Visualization
Big data visualization refers to the implementation of more contemporary visualization techniques to illustrate the relationships within data....
-
The Components of Data Fabrics
A data fabric is an architecture and set of data services that provide consistent capabilities across a choice of endpoints spanning....
-
The Future of Data Storytelling
Data storytelling is the best way to use data to create new knowledge and new decisions or actions. It is an integrative practice ....
-
Types and Benefits of Data Cataloging
A data catalog is a detailed inventory of all data assets in an organization, designed to help data professionals ....
-

A New Software for Time Series Data Prediction
Making predictions using time-series data typically requires several data-processing steps and the...
-

Why Is Blockchain The Next Big Thing For Data Science?
Innovative technologies such as big data and blockchain are being hailed as the next .....
-

Data Automation
Business intelligence topics wouldn’t be complete without data (analysis) automation. In the last decade, we saw so much data....
-

Data Breach
A data breach is an incident wherein information is stolen or taken from a system without the.....
-

Data Cleaning Tools and benefits
Data cleaning is the crucial process of identifying and resolving broken, inaccurate, or unnecessary data. Data defects....
-

Data Modeling
Data modeling is the process of creating a visual representation of either a whole information system or parts of it to communicate ......
-

OCI Expands its Security to Safeguard Customers Data
Cloud major Oracle on Tuesday said it is expanding security services .....
-

ML Used to Predict the Age and Gender of Infant Using Temperature
A new study in PLOS ONE used machine learning to ....
-

India Replace Weather Balloons Sensors with Drones to Collect Atmospheric Data
India is set to deploy drones to gather atmospheric data that is .....